

MariaDB has been a prominent name in the world of hosting for a long time now. CloudSigma PaaS combines the best practices of MariaDB hosting and analysis on our platform in the form of CloudSigma MariaDB-as-a-Service. This service is designed to automate the technical aspect of the process and allow you to use a ready-to-work solution at a moment’s notice.
Here are just a few of the benefits of using MariaDB-as-a-Service, powered by CloudSigma PaaS: 
- Automated installation
As you will see ahead, installation can be performed very easily.
- Cluster reliability
The service operates on the multi-instance database structure which prevents downtime and makes the cluster much more reliable.
- Default optimization
Based on the kind of environment you choose, the service will automatically configure itself to ensure the best performance.
- Reduced time-to-market
It only takes a few steps for you to set up a fully functional MariaDB database which reduces time-to-market significantly.
In this guide, we will aim to highlight the advantages of MariaDB-as-a-Service and how you can set it up on CloudSigma PaaS with just a few clicks.
MariaDB Clusterization- What Challenges Does it Help You Conquer?
Downtime is one of the major challenges that all developers have to counter. Even a little bit of app downtime can end up costing a significant amount in the long run. In fact, just take a look at how much downtime ended up costing the following e-commerce companies per minute:
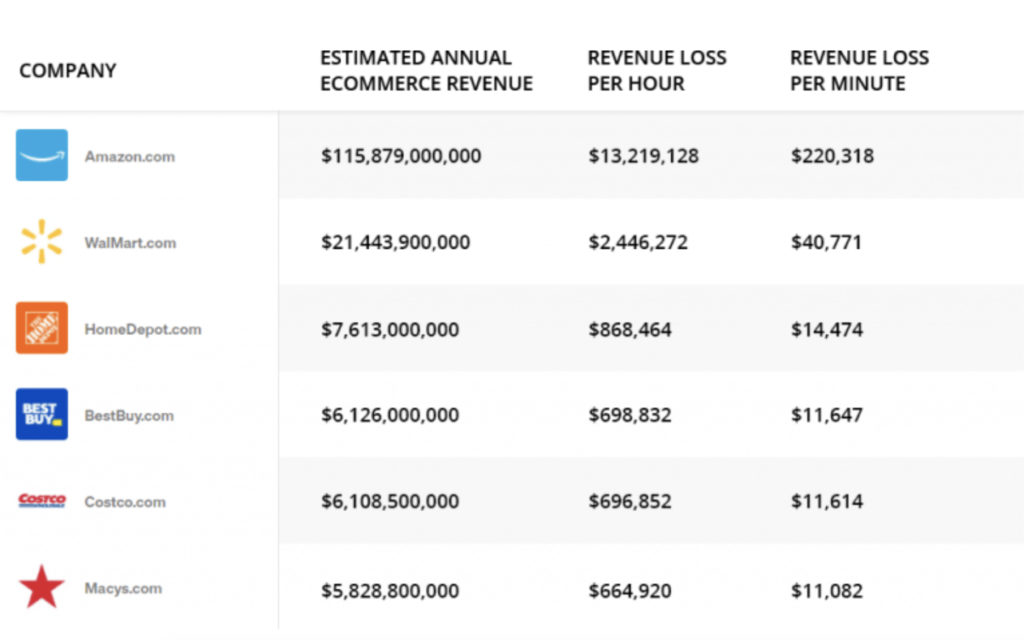
Not only does downtime cause immediate revenue loss, but it also has disastrous consequences in the long run. Websites or applications that are known to experience downtime frequently may be avoided by people, causing you to lose both existing and new customers. As such, businesses should make it a priority to minimize downtime or avoid it altogether however possible.
If you are using standalone topology, avoiding downtime will be difficult, if not impossible. That is because you always have a single point of failure. On the other hand, clustered solutions eliminate this problem and ensure higher availability. However, clustered solutions also tend to be more difficult to set up and maintain in the long run. Say you want to configure a clustered system using MariaDB. This is what your list of tasks would typically look like:

- Create the required number of server nodes.
- Add MariaDB repositories to each node.
- Install MariaDB on each node individually.
- Configure every server in the cluster based on your requirements.
- Open the firewall on each server to allow communication between the nodes.
- Install and configure SQL Load Balancer.
- Start the cluster.
- Ensure the nodes and the cluster are operating as per configuration.
- Perform routine maintenance and regular software updates in a timely manner.
For relatively inexperienced users, this list can sound exhausting and take up way too much time when executed. The good news is that there is a very straightforward solution. Like most companies today, you can opt to use Databases-as-a-Service. Here is a breakdown of the various options you have at your disposal in this regard:
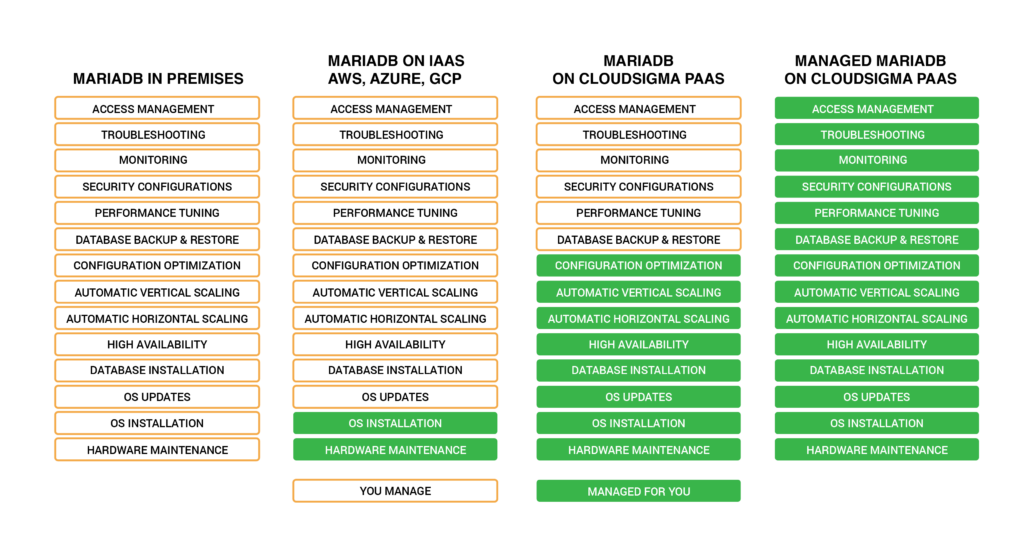
- On-Premises
It offers no automation, meaning all aspects of the hosting must be managed by the user manually.
- Infrastructure-as-a-Service (IaaS)
IaaS offers automation only for the operating system and hardware maintenance.
- Self-Service Platform-as-a-Service (PaaS)
Self-service PaaS will automate the installation and maintenance and allow you to handle the management of the database. An example of this would be the self-managed MariaDB hosting offered by CloudSigma PaaS as a default option for every customer.
- Managed Platform-as-a-Service
Managed PaaS will automate everything from package installation to database management. In the end, you get a ready-to-work solution that can be deployed immediately. CloudSigma’s MariaDB-as-a-Service solution is an example of this.
MariaDB-as-a-Service on the CloudSigma PaaS
CloudSigma PaaS allows the user to implement clusterization for their MariaDB database by simply flicking a switch in the Topology Wizard:
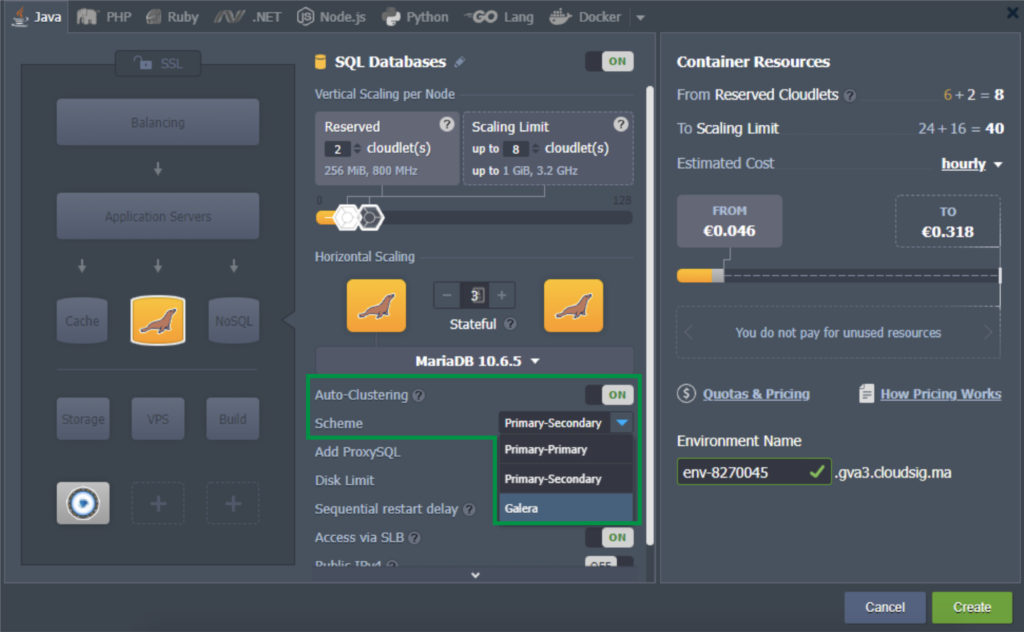
Database Replication Scheme
You get to choose between three different types of MariaDB replication schemes. The intuitive GUI makes configuration very straightforward and easy.
- Primary-Secondary Replication
The default replication scheme that is selected when you turn the Auto-Clustering switch on is the Primary-Secondary scheme. This scheme fits the most when the main load is reading:
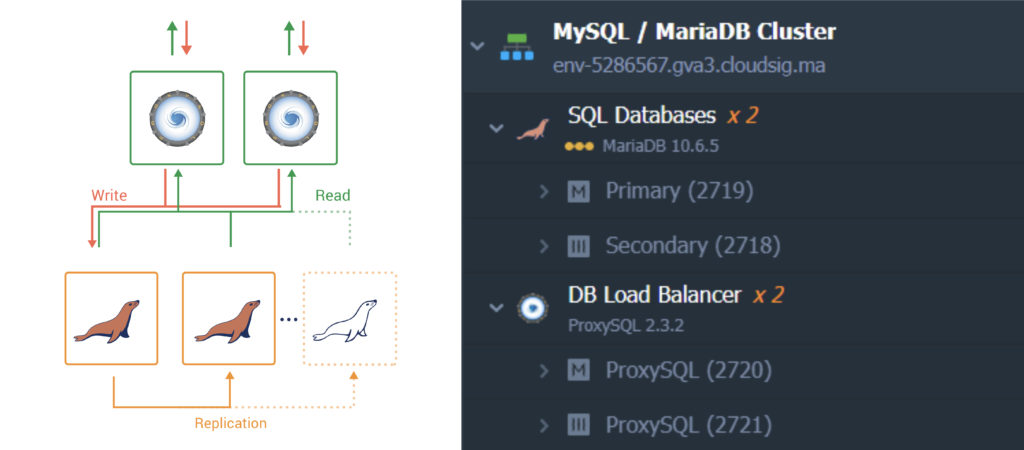
For the Primary-Secondary topology, we need to provide two nodes- one being the primary and the other being the secondary. The proxy SQL servers are provisioned for load balancing of SQL queries. Here is a list of the parameters that are automatically configured for this topology:
|
1 2 3 4 5 6 7 8 9 10 |
Server-id = {nodeId} binlog_format = mixed log-bin = mysql-bin Log-slave-updates = ON expire_logs_days = 7 relay-log = /var/lib/mysql/mysql-relay-bin relay-log-index = /var/lib/mysql/mysql-relay-bin.index replicate-wild-ignore-table = performance_schema.% replicate-wild-ignore-table = information_schema.% replicate-wild-ignore-table = mysql.% |
- Primary-Primary Replication
If you choose the Primary-Primary topology, you will need to create two database nodes in the primary mode and two ProxySQL load balancers in front of the cluster. This replication scheme is suitable when the application is actively writing to and reading from the databases:
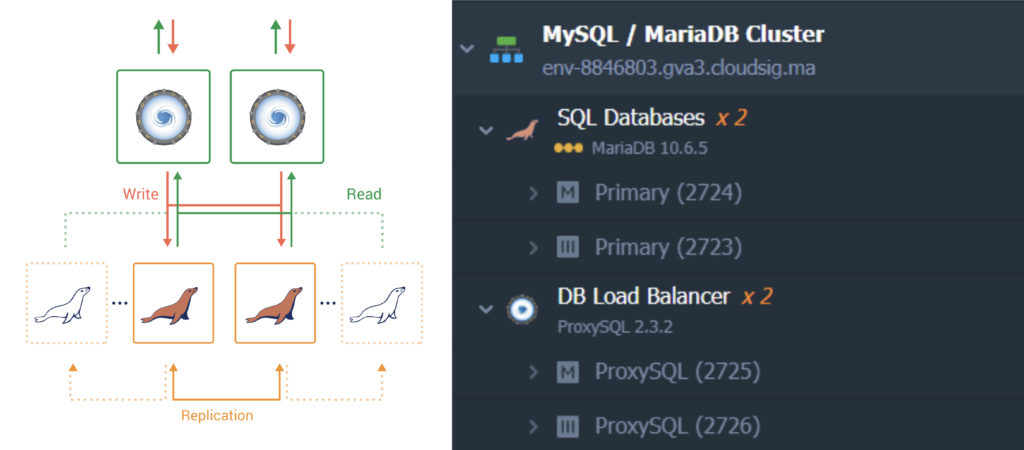
Here is a list of the parameters that are automatically configured for this topology:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
server-id = {nodeId} binlog_format = mixed auto-increment-increment = 2 Auto-increment-offset = {1 or 2} log-bin = mysql-bin log-slave-updates expire_logs_days = 7 relay-log = /var/lib/mysql/mysql-relay-bin relay-log-index = /var/lib/mysql/mysql-relay-bin.index replicate-wild-ignore-table = performance_schema.% replicate-wild-ignore-table = information_schema.% replicate-wild-ignore-table = mysql.% |
- Galera Cluster Replication
Lastly, you can opt for the Galera cluster. When you choose this scheme, three MariaDB and two proxy SQL nodes are added by default. The Galera cluster is best suited if you need to make a HA database cluster distributed across far-off regions. Remember, when creating distributed topologies, you need an odd number of nodes to maintain a quorum so that split-brain issues can be avoided in case of a network failure:
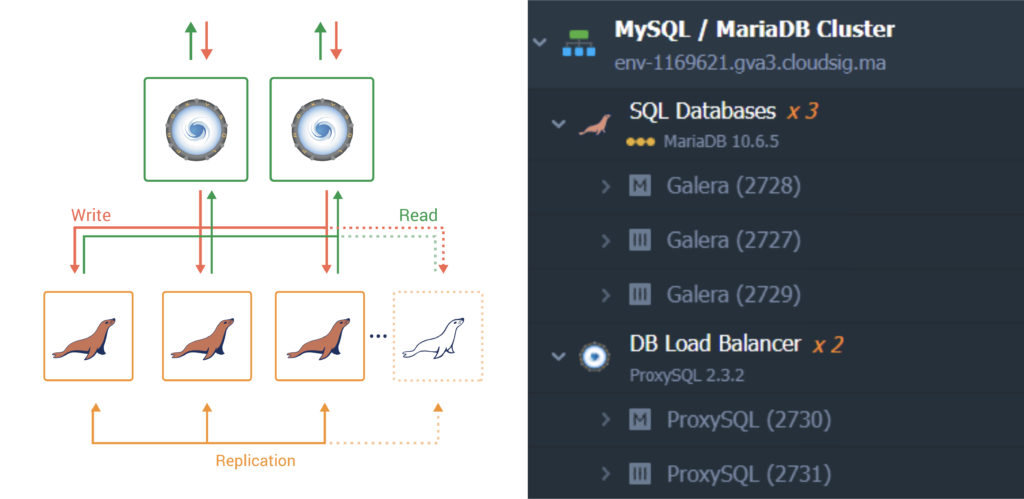
Here is a list of the parameters that are automatically configured for this topology:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
server-id = {nodeId} binlog_format = ROW # Galera Provider Configuration wsrep_on = ON wsrep_provider = /usr/lib64/galera/libgalera_smm.so # Galera Cluster Configuration wsrep_cluster_name = cluster wsrep_cluster_address = gcomm://{node1},{node2},{node3} wsrep-replicate-myisam = 1 # Galera Node Configuration Wsrep_node_address = {node.ip} Wsrep_node_name = {node.name} |
Automatic Vertical Scaling
The MariaDB instances are run inside isolated system containers which keep changing the amount of allocated resources such as RAM and CPU dynamically based on the demands at any given time. All you need to do is specify your maximum limit during configuration:
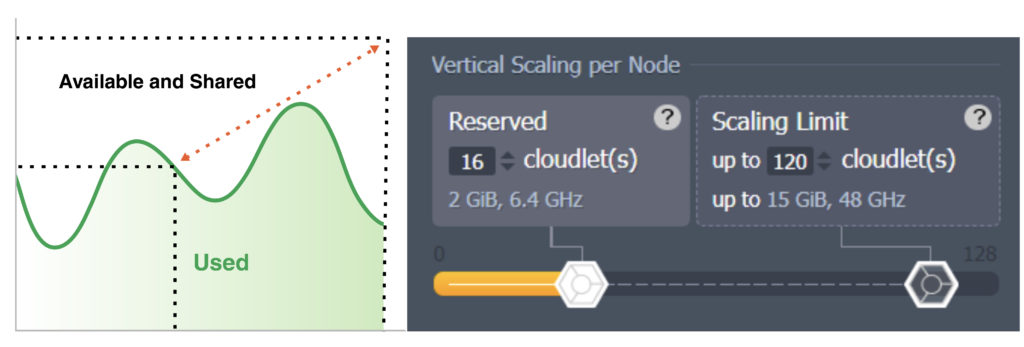
Based on your scaling limit, the platform will reconfigure the database parameters automatically:
|
1 2 3 |
key_buffer_size = ¼ of available RAM if total >200MB, ⅛ if <200MB table_open_cache = 64 if total >200MB, 256 if <200MB myisam_sort_buffer_size = ⅓ of available RAM innodb_buffer_pool_size = ½ of available RAM |
If you want to, you can also change these parameters manually in /etc/my.cnf.
Automatic Horizontal Scaling
Horizontal scaling is just as easy too. You can add or remove instances in the topology wizard by just clicking on “+” or “-”. In addition, it is possible to preselect the scaling mode according to which the added nodes will either be Stateless (new) or Stateful (clones of the primary layers):
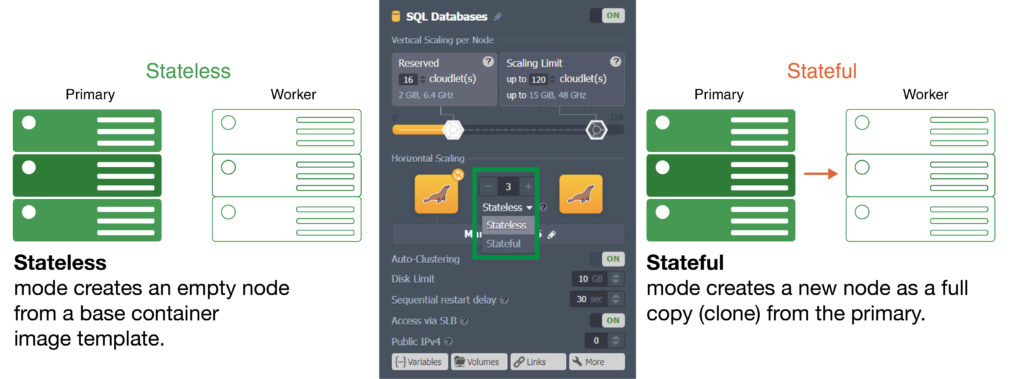
You can set up custom triggers for when the platform should automatically scale nodes. This can be based on the CPU, RAM, Network, or Disk usage:
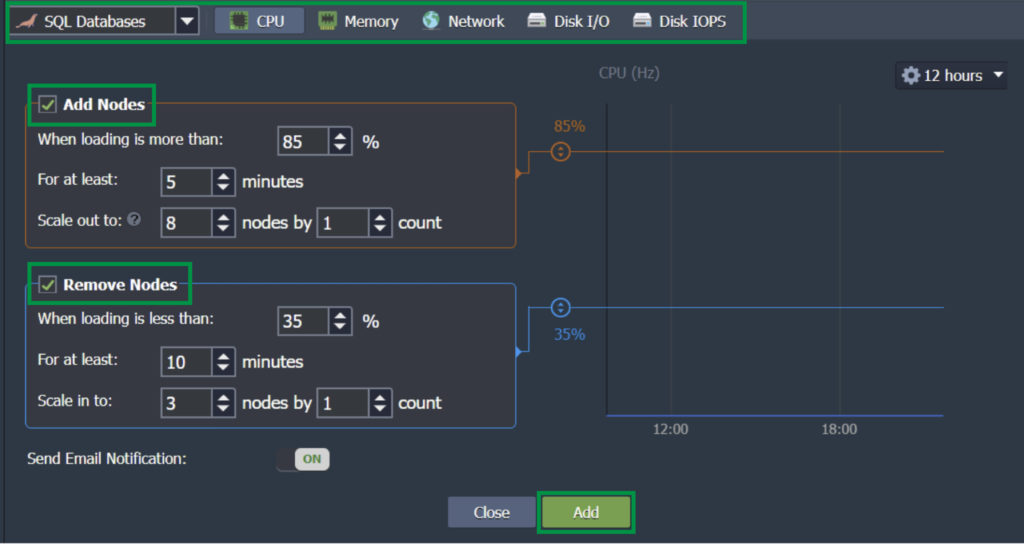
If you turned on auto-clusterization, the new nodes will be added based on the cluster scheme:
- Primary-Secondary Scaling
When you add a new database node, the Primary-Secondary scaling logic goes through the following steps:
- Select a secondary node in the topology.
- Drop the secondary node from the ProxySQL balancer distribution list.
- Stop the secondary. A primary’s binlog position is fixed automatically.
- Clone the secondary (stateful horizontal scaling).
- Start the original secondary and return it to the ProxySQL distribution list.
- Reconfigure server-id and report_host on the new secondary.
- Launch the new secondary. Add it to ProxySQL.
- Once the skipper transactions are applied to the new secondary and catch up with the primary, the new secondary will be added to the distribution by ProxySQL.
- Primary-Primary Scaling
Primary-Primary scaling always uses a primary to make new secondaries. The process is similar to Primary-Secondary scaling:
- Define a second primary node in the topology.
- Drop the 2nd primary node from the ProxySQL distribution list.
- Stop the 2nd primary. The binlog position is fixed automatically.
- Clone the 2nd primary (stateful horizontal scaling).
- Start the 2nd primary and return it to the ProxySQL distribution list.
- Reconfigure the cloned node as a new secondary (disable primary configuration).
- Launch the new secondary. Add it to ProxySQL.
- The first primary will be selected for further scaling.
- There is a sequential choice of primaries as further secondaries allow to distribute equally secondaries between primaries.
- Galera Cluster Scaling
The topology for the Galera cluster is a bit different. We will use stateless scaling mode with another technique to catch up with the current database state. The algorithm stages are as follows:
- Add a new node (stateless horizontal scaling).
- Before adding the new node to the cluster, preconfigure wsrep_cluster_name, wsrep_cluster_address, wsrep_node_address and wsrep_node_name.
- Add the new node to the cluster.
- Add the new node to ProxySQL but not for distribution.
- The cluster will automatically add a donor from the existing nodes. It will also do the State Snapshot Transfer from it to the new node.
- As the synchronization finishes, ProxySQL will include the node in the distribution of the requests.
Load Alerts- Default and Custom
Load alerts on the CloudSigma PaaS are meant to automatically detect and inform you when the resource usage has reached close to your specified limit. You have the capability of modifying default alerts based on your particular requirements. You can also add tracking for more conditions, for example, when a particular resource type is above/below the stated value (%) during a given time period:
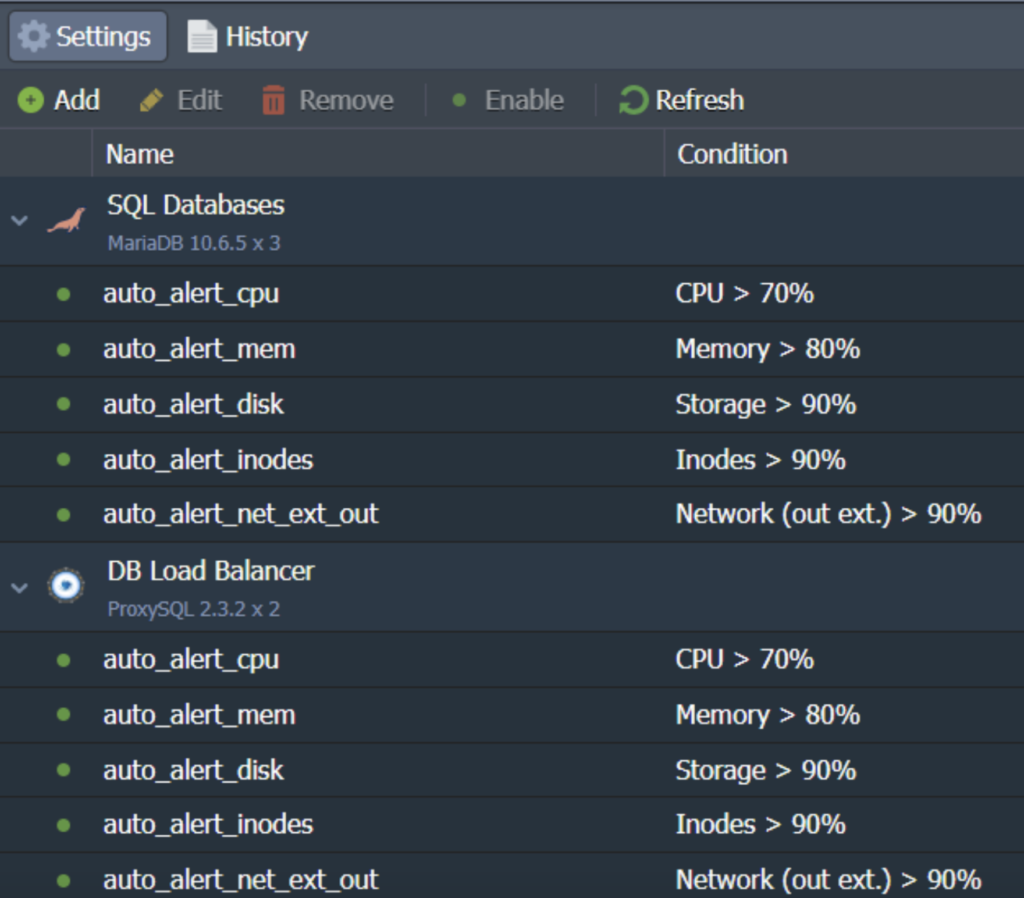
Any time a load alert is triggered, you will receive an email notification on your registered email about the application’s load change.
Anti-Affinity Rules
CloudSigma PaaS enables high availability and failover protection by creating all newly added containers of the same later at different physical hosts:
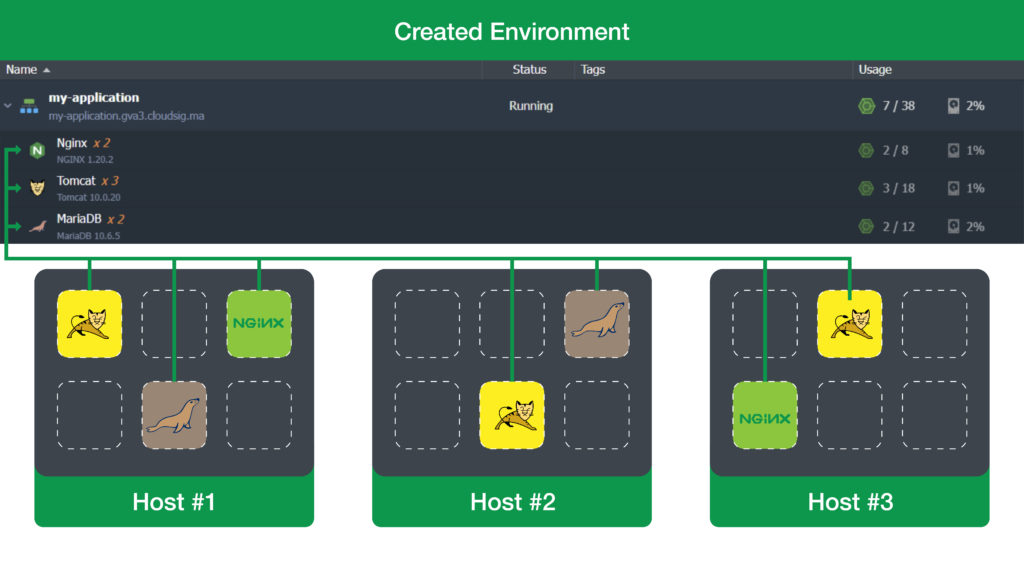
Thus, if a replication topology comprises two nodes, each will be deployed on a different host, as seen above. This is done so that if one physical node fails, the database can continue to work on the other hosts without any downtime.
Automatic Handling of OOM Killer Events
There may be instances when your application runs out of memory. In such a case, there are two paths of resolution: either the OS crashes the entire system or it terminates the process that is consuming all the memory (which is the application in our case). The better option is for the app process to end as opposed to the OS crashing.
An OOM is an Out-Of-Memory Killer. It is the process that terminates the application to prevent the kernel from crashing. OOM Killers are important on the CloudSigma PaaS as it sacrifices the app for the kernel. In case the MariaDB process is terminated forcibly, a message will appear in the log file /var/log/messages to offer information on why the OOM killer was triggered.
If the OOM killer ends the MariaDB process, the CLoudSigma platform will automatically adjust the database configs, reducing the innodb_buffer_pool_size parameter by 10%. After that, the system will relaunch the container to restart operations. If such a scenario recurs, the autoconfiguration cycle will be repeated.
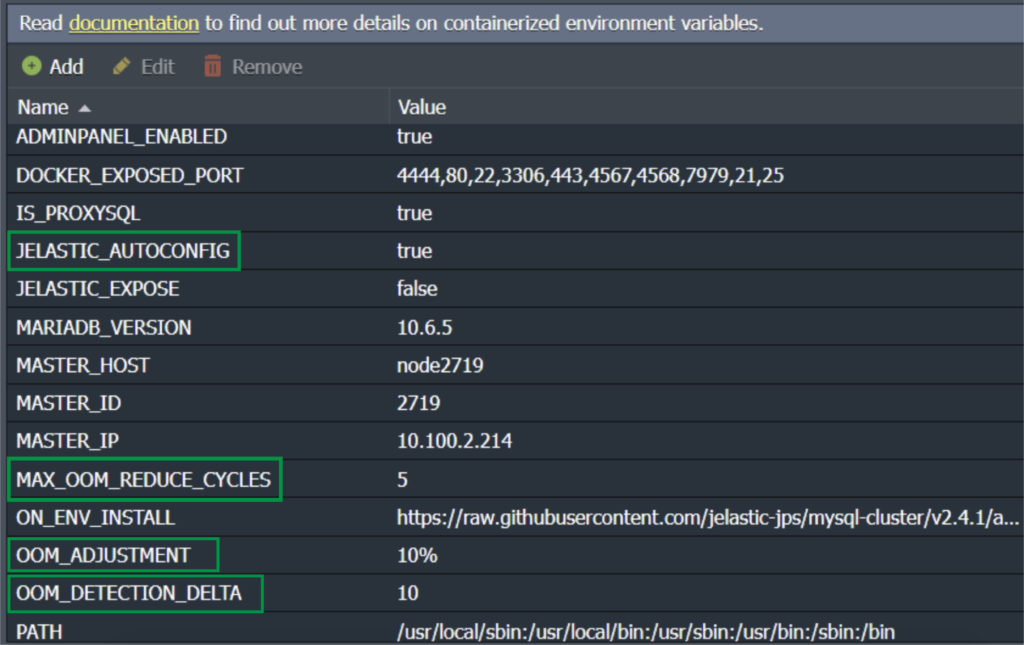
It is possible for the user to customize the environment variables and modify system behavior in regards to OOM kill scenarios:
- JELASTIC_AUTOCONFIG
Enables/disables (true/false) CloudSigma PaaS autoconfiguration.
- OOM_DETECTION_DELTA
Sets the time interval for CloudSigma PaaS to analyze the /var/log/messages log after service restarts to determine if the OOM killer caused it. By default, this is set to two seconds.
- OOM_ADJUSTMENT
Defines a value in %, MB, GB that the current innodb_buffer_pool_size parameter should be reduced after each restart caused by the OOM killer. It is set to 10% by default.
- MAC_OOM_REDUCE_CYCLES
Configures a maximum number of cycles for innodb_buffer_pool_size reduction. It is set to 5 times by default.
You can see these variables as follows:
This guide has familiarised you with some of the most important specifics regarding MariaDB hosting on the CloudSigma PaaS platform. MariaDB-as-a-service on the CloudSigma PaaS serves to make database management as easy and non-time consuming as possible for its users. Not to mention, the high availability and cluster reliability bring the added bonus of almost no downtime to your application or website. If you would like to give it a try, head over here to get a free trial of one of the best PaaS platforms currently available, or contact us if you have any queries.
- 5 Tips to Achieve Optimal Cloud Computing Cost Efficiency - October 31, 2022
- CloudSigma Empowers Blockchain Infrastructure Provider with a Green, Reliable, and Cost-Efficient Cloud Platform - October 27, 2022
- Whitech Launches New Egypt Cloud Computing Offering, Powered by HPE and CloudSigma - October 17, 2022
- Key Aspects of Protecting your Data in the Cloud - September 20, 2022
- How to Configure MongoDB Replication and Automated Failover - September 19, 2022