

Introduction
When working on cloud infrastructure, your primary concern is making sure your applications are fully operational. One important inclusion of your setup and deployment process is to build effective, thorough, and robust security measures into your apps or systems before they are offered to the public. Instead of retroactively implementing security measures post-deployment, it is important to ensure that there is a secure base configuration built into your infrastructure.
This tutorial will assist you in this regard. It will highlight certain practical security measures that can be implemented while your server’s infrastructure is being set up and configured. While this is not an exhaustive list of server security protocols, it is a helpful starting point. As you work with and better understand the specific needs of your environment and applications, you can develop additional security measures to help build upon your base.
SSH (Secure Shell) Keys
While you work with your server, a great majority of your time will be spent working in an SSH connection with your server on a terminal session. Security shell (SSH) keys, provide a safer log-on method to the server than logins that rely on passwords. For the purpose of authentication, with the use of SSH keys, two access keys are prepared. The first is a secret (private) key while the other is a sharable, public key.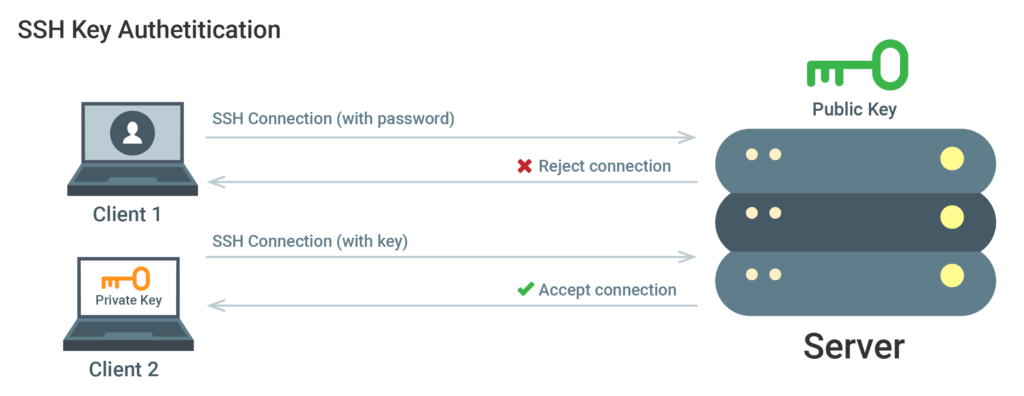
The SSH key authentication must first be configured. This is accomplished by placing the SSH public key in the proper directory on the server. As your client initially connects to the server, you will be asked for proof of possession of the private key. This is done by a generation of a random value that will then be sent to your SSH client. The SSH client, in turn, will use the private key in the encryption of a response. This response will be sent to the server. Next, the server will decrypt the message from the client with the use of your public key. If the random value is decrypted by the server, it indicates that the client has the private key. In that case, authentication is confirmed and a connection to the server without a password can be established.
Enhancing Security with SSH Keys
While password authorization or any authentication with SSH is completely encrypted, server access can be attempted by malicious users. Especially if they have come to possess the server’s public-facing IP address. By trying every possible key combination, modern computing does permit password-based log-ins and is often attempted by malicious users. If one was to automate these access attempts, it is possible by trying different combinations systematically to finally access the correct password.
By leveraging SSH encrypted authentication, there is no need to enable passwords for logging in. SSH keys typically contain a significant possibility of combinations that would need to be performed by an attacker. The increased number of bits multiplies the potential for different combinations needed to crack the encryption. To run through as many possible combinations of the SSH key algorithm, therefore, would be immensely time-consuming. Thus, it becomes a venture not worth a malicious attacker’s time. This is why the SSH encryption is typically deemed ‘uncrackable.’
Implementing SSH Keys
Logging on to any remote Linux server should use SSH keys. A local machine can be generated on the local machine end, with the public key to the server transferred back within minutes. With this tutorial, you will get a basic idea on how to use SSH to connect to a remote server in Ubuntu. You can also follow our in-depth tutorial on how to configure your Linux server to use SSH key-based authentication.
Overall, not permitting the root user to login directly over SSH is a commonly utilized best practice, whereas logging in as an unprivileged user and using a tool like sudo to escalate privileges as needed. This is known as the principle of least privilege: a method of limiting access permissions. Once the login as an unprivileged account has been verified with SSH, root logins can be disabled by setting PermitRootLogin no directive /etc/ssh/sshd_config on your server. Then, the server can be restarted with an SSH process command sudo systemctl restart sshd.
Firewalls
A software (or hardware device) that regulates the exposure of services to the network is known as a firewall. A firewall, optimally configured, ensures that only permitted services are available publicly and allowed in and out of the particular server.
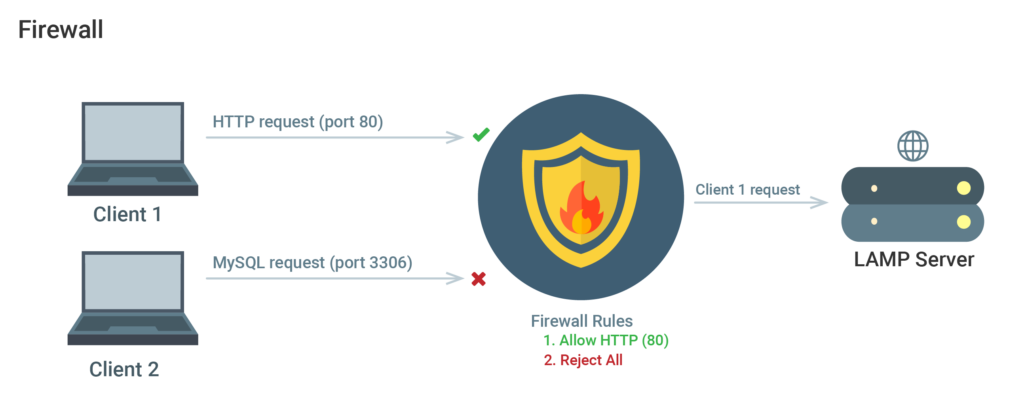
Several services can be running by default on a server and these can be categorized into the following groups:
- Internal services: These should only be accessed internally from the server itself. This prevents exposure of the services from publicly available internet accessibility (ex: a database reachable only via local connections).
- Public services: Services that can be accessed by anyone, often anonymously, on the internet. These include web servers that permit your site to be accessed by visitors.
- Private services: Only authorized accounts from an exclusive set of locations can access these services (ex: phpMyAdmin database control panel).
While public services can be left available to be accessed from the internet, private services can be restricted based on access parameters (such as connection types), and internal services are shut off any internet-based access entirely. The access to these services, along with the granularity of which it is permitted is all controlled by the firewall. Unused ports are commonly configured to block access to them entirely.
Security Enhancement With Firewall Use
A firewall is a baseline for server protection. It serves to limit connection to and from services before the application handles the traffic. Of course, you can implement additional security features for your services and restrict them to the desired interfaces.
Only the services that you choose to remain open will not be restricted by a properly configured firewall. This limits the elements vulnerable to exploitation as the pieces of software available are a lot more limited and therefore less likely to experience an attack.
Implementing Firewalls
Many firewalls are available for Linux systems. Some of these are quite complex. However, the typical setup of a firewall should only need to be done at the time of the server’s initial setup when changes to the services from the server are implemented. This should take only a few minutes of your time. The following are some options to consider for getting the firewall set up and activated:
- For CentOS, you can follow our Setting Up a Firewall with FirewallD on CentOS 7 guide.
- Our Iptables guide can walk you through listing and deleting Iptables firewall rules.
Most importantly, regardless of the tutorial, you must assure that the firewall of choice blocks unknown traffic from your servers in order to prevent any newly available services from being exposed on the internet inadvertently. By needing to explicitly authorize access you will be prompted to fully evaluate how a service is accessed, run, and who it is permitted to be accessed by.
Virtual Private Cloud (VPC) Networks
Your infrastructure’s resources need to operate inside of a private network known as the VPC. These networks are more secure as they prevent access from other cloud-based VPC networks. Thus, they render the network’s interfaces inaccessible from the public internet.
Enhancing Security with VPC Networks
Private networks are preferable to the public counter networking counterpart for internal communication. VPC permits the isolation of resource groups into particular private networks. Because VPC networks interface only through private connections, the network’s traffic is guarded against exposure to the public internet, where that information could be vulnerable to interception or exposure. VPC networks can also be used to isolate execution environments, as well as tenants. Internet gateways can also be set up as a single point of access between the public internet and the resources on your VPC network.
In addition, a large part of security entails analyzing our systems and securing all the components to the best of our ability. Service auditing permits us to know the systems’ acceptable protocols, services running, and which ports are being utilized for communication. Knowing this information can help make the best decisions concerning configuration. Such decisions could be firewall settings, system monitoring and alerts, and which services should be accessible publicly.

Leveraging Auditing To Enhance Security
Each service can be utilized for handling external clients or for internal purposes. Regardless of intent, these services are all vulnerability points to malicious users. As the number of services running increases, as does the potential of vulnerability exploitation.
You can begin analyzing services once you have a firm grasp on what services a machine is running. When running a service audit, the following questions are beneficial to ask:
- Should the particular service be actively running?
- Is it running on the optimal network interfaces?
- Is the service best suited for a public or private network interface?
- Are the firewall rules correctly configured to permit legitimate traffic to this service?
- Is illegitimate traffic blocked with my firewall rules?
- Is there an alert system about security vulnerabilities enabled?
When adding a new server to the infrastructure, the above should be standard practices in its configuration process. An additional benefit of services audits is that they will allow any of the configurations that have changed unintentionally to be identified.
Performing Services Audits
In order to audit the running services use the ss command to list all of the UDP and TCP ports actively used on a server. Here is an example of using the ss command with a program name PID, checking for listening TCP and UDP ports:
|
1 |
sudo ss -plunt |
Something similar to the following will be returned:

Your main focus should be on the Netid, Local Address:Port, and Process columns:
- If the Local Address:Port value is 0.0.0.0 it means that the service is actively accepting all connections across all IPv4 network interfaces. If the address is [::] then all IPv6 connections are accepting traffic.
- In the above example, both the Nginx and SSH are listening across all public interfaces on both networking stacks (IPv4 and IPv6).
With the above example, you could choose if you need to permit SSH and Nginx to listen on the two interfaces, or just on either one. Generally, you would want to disable any services that are unused to keep them from running. For instance, if your site should just be reachable through IPv4, it would help to turn the IPv6 interfaces off to limit the exposure.
Keeping Up To Date With Unattended Updates
Unattended updates bring down the degree of effort required to keep your servers secure and help to lessen how long they remain exposed to known bugs. The longer it takes you to get to running updates on your server, the longer it remains exposed to known vulnerabilities. Unattended updates will make sure that as soon as fix packages are available, they can be automatically installed on the server to limit the time of vulnerability.
In addition to server auditing, unattended updates can vastly reduce exposure to attacks. They will also greatly reduce the time spent on server maintenance.
How Unattended Updates Are Activated
Unattended updates are now an optional feature on most server distributions. On Ubuntu, for instance, the administration can run the following command:
|
1 |
sudo apt install unattended-upgrades |
For additional information on implementing unattended updates, check out the Automatic Updates section here. For Fedora, the instructions can be found here. Please note that the auto-updates will only install the software that is initially installed through your system package management system. Any supplemental applications, such as web-based ones, will need to be separately checked for updates manually or individually configured for automatic updates.
Directory Indexes
When a directory lacks an index file, most servers are configured to display directory indexes by default. In other words, if a directory called ‘downloads’ was created on your web server, anyone browsing that directory will be able to see all of the files in it. While this is not always a security risk, it does put confidential information visible to eyes not privy to it. As an example, consider that your web server may have a file that contains your website’s homepage access credentials and a file with all of the configurations to the back end of the site’s database. If directory indexes aren’t disabled, these files will be seen by anyone browsing that directory.
Increasing Security Through Directory Index Disabling
Even though directory indexes are useful, they can leave files unintentionally exposed. To mitigate such unintentional exposure and any associated risks, the directory indexes on the server should be disabled by default. While the files can still be reached by visitors, the exposure to unintentional data viewing is significantly limited.
Disabling Directory Indexes
In most instances, an addition of just one more line to your web server’s configuration is sufficient to disable directory indexes.
- Follow these steps to disable these directory listings on the Apache Wiki. Assure that Options -Indexes are listed in the configurations blocks Apache Directory.
- Indexes are disabled by default on Nginx, requiring no further action in this regard.
Frequent Backups
Even though backups are not a security measure, they are imperative for safeguarding data and entire systems in case of the system being compromised. It also helps to analyze how the system could have come to be under attack. Consider an unfortunate scenario where your system is attacked by ransomware (a virus or malware tool that encrypts the files on your system, only decrypting them, if you pay the hacker money). If there are no backups of data, your only choice is to pay the money to get access to your data back. If data is securely backed up, you will still have access to it and be able to recover the data without needing to access the compromised system.
Security Enhancement Through Frequent Backups
Frequent backups help recoup information on account of the attack, corruption, or even unintentional loss (deletion). No matter what type of negative events leads to data loss, the risk is lessened by the retention of copies of server data.
Aside from ransomware attacks, frequent backups can help with the measurable investigation of long-term system assaults. If you are not safely storing your data off in a backup form, determining the attack’s source and which data was compromised can be challenging or even impossible.
Implementing Frequent Backups
Treating verifiable recovery of corrupted, compromised, or deleted data as the goal of your recovery efforts when backing up your systems is paramount. To frame it best, consider what actions would require the least amount of work to get you back up and running if your server was to disappear tomorrow.
Here are some other points to consider when thinking about a disaster recovery plan:
- If you are operating with dynamically changing data, your backups will likely need to be more frequent. In case of data loss, if your last backup was too long ago, you might be forced to go back to stale data.
- Think about the actual backup restoration process. Will a new server need to be added for it or can the existing one be restored?
- What is the longest period of time that you can have the server not be operational?
- Is offsite backup a necessary solution?
To learn more about CloudSigma’s Disaster Recovery solutions check out our blog post detailing why our Disaster-Recovery-as-a-Service is the perfect companion to the cloud. And here you can find out more about CloudSigma’s security & business continuity features. We also have a detailed guide on how to easily set up CloudSigma’s backup functionality.
Private Networking and VPNs
A private network is one that is only available for access and uses to particular users or servers. A secure connection between remote devices that enables the connection to operate as if it is in a private network is a VPN (a virtual private network). It provides you the ability to secure connections in a private network and to connect remote servers.
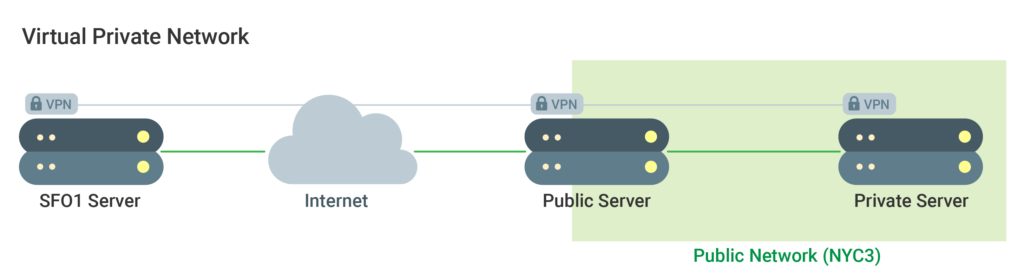
How Do Private Networks Enhance Security?
When there is a choice of using public versus private networks for internal communication, the latter is always the preferable option. Keep in mind, however, that other users from within the data center are still able to access the same network. That means that supplemental security measures must still be applied to assure communication between servers is safe.
Essentially, utilizing a VPN is an approach to delineate what your organization’s workers can see. Correspondence will be completely secure and private. Application configurations would permit virtual interface traffic to be passed through the VPN. By doing so, only those services intended for client interaction via the internet will be allowed to be exposed to a public network.
How Difficult Is It To Implement a VPN?
Leveraging private networks is as simple to do for your data center as it is to configure your applications and firewall to use a private network and the enabling of the VPN during your server’s creation. It is important to recall that other servers share the same network space as center-wide private networks.
The initial setup of a VPN is slightly more complex. However, the added security this adds is worthwhile for the majority of use cases. The configuration data and shared security need to be installed and configured on each server on the network. For more in-depth information on how a VPN works and an overview of setting up OpenVPN on Ubuntu follow this guide. You can also follow this tutorial that walks you through the steps to connect a VPN network to CloudSigma’s infrastructure.
SSL/TLS Encryption And Public Key Infrastructure
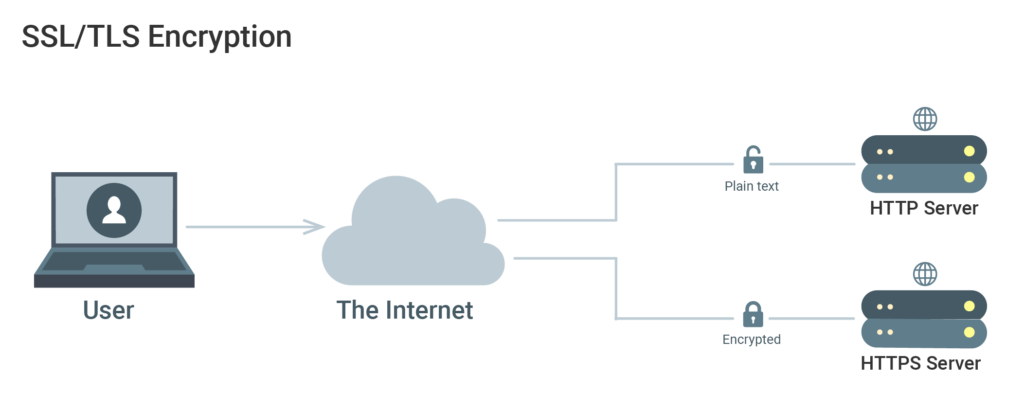
Generation, management, and validation of certificates to identify individuals and communication encryption are referred to as Public Key Infrastructure (PKI). Different entities can be authenticated to each other with the use of SSL or TLS certificates. After that, they can also be used for establishing encrypted communication.
How Certificates Enhance Security
In order to encrypt traffic and validate member identities on a server, it is vital to establish certificate authority (CA) and to be able to see all of your network’s certificates. This can help prevent ‘man-in-the-middle’ attacks, in which the server is imitated by a hacker, and traffic is redirected away.
The configuration of each server can be set up to trust a centralized CA. Any subsequent certificate signatures can then be trusted implicitly. If SSL/TLS encryption is supported by the protocols and apps your server uses, you can secure your system without the VPN tunnel overhead. For further information follow our tutorial on how to automate LetsEncrypt SSL certificate renewals for Nginx.
Difficulty Of Implementation
There can be a lot of initial effort in configuring a certificate authority and then setting up the remaining PKI. Also, when new certificates need to be created, revoked, or signed, additional administration effort will be required.
Because most infrastructures need to grow, implementing a full-fledged PKO is the most sensible approach. Until you reach a point where PKI is worth the extra administration costs, utilizing a VPN to secure the system’s components can serve as an adequate stop-gap measure.
Detecting System Intrusion And Utilizing File Auditing
File auditing is a process used to compare the files and their attributes of your system in a fully secure, good state to those of your system currently. This is a good method to find and isolate unauthorized system changes.

An IDS, intrusion detection system, refers to monitoring software that keeps tabs on any unauthorized activity on the system. Generally, it uses file auditing methods to seek out any unexpected system changes.
IDS/File Auditing Enhancement Of Security
Beyond just service-level auditing, performing file-level audits is essential to ensuring the security of your system. This can be done either by an automated IDS process or periodically performed by the system administrator.
File audits and IDS are the only true processes to make certain that the system did not experience any unanticipated alterations. Most intruders want to exploit servers they invade for extended periods of time, and in order to do so, they must retain the ability for their actions to be covert. They could replace binaries with vulnerable or compromised versions. Any files that have been altered in the system will be detected by a filesystem audit. This allows you the comfort of knowing very quickly if the system’s integrity had been compromised.
Level Of Implementation Difficulty
The implementation of IDS and file auditing can be a very intense process. At the start, the system must be configured to define paths to exclude and establish non-standard changes that had been made to the system in order to create a baseline reading of the system.
Day to day operations also become more cumbersome as procedures will need to re-check the system before any updates are run. The baseline of system measurements will also need to be recreated or re-established to pick up software version changes as part of the system’s new baseline. The auditing reports will also need to be transposed to an alternate location. That’s because you need to prevent a system intruder from altering the audit to remain hidden by covering their tracks.
While this certainly increases the administrative load of your system, it is one of the only sure-fire way to ensure that none of the files have been altered without your knowledge. Some of the most popular intrusion detection and file auditing systems are Aide and Tripwire.
Isolated Environments
Any method where individual components are run in their own dedicated space is referred to as isolated execution environments.
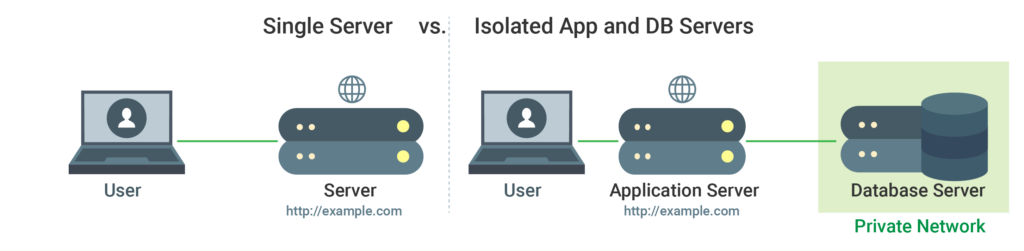
This could denote that particular application components will be housed on their own dedicated servers, or that your services may be configured to operate in chroot environments (or containers). How isolated the environment mostly depends on the realities of your infrastructure, and your application’s requirements.
Enhancing Security With Isolated Environments
By isolating your process into individual environments, you are also isolating which processes could be affected by security flaws. Much like compartments and bulkheads help to contain hull breaches on ships, when you separate your system’s individual parts and components, if an intruder gains access to one of them, they have not been able to get to the whole interconnected network system.
Difficulty Of Implementation
The complexity of isolating your applications varies depending on the containment types you decided to use. Docker does not consider isolation a security feature. However, when your components are split between different containers, the isolation is achieved much more readily. You can follow this tutorial to install Docker on our infrastructure.
When chroot environments are set up, there is some degree of isolation afforded as well. However, this is not a completely impenetrable method as there are methods of breaking out of such an environment. Dedicated machines for varying components are typically the best and simplest way of achieving isolation. However, it is more costly due to the necessity of additional machines.
Final Thoughts
The provided strategies are just some of the steps that you can take in order to increase your system’s security. It’s worth noting that the longer you wait to implement the security features, the lower their efficacy becomes. With that in mind, it is important to assure that security should not be waited on. Instead, it should be implemented as one of the first provisions of building infrastructure. Once your system is sufficiently secure with baseline protections, you can begin activating services and appending applications, while knowing that they are defaulting their runs in a secure environment.
Security is not a stagnant process, however, but a fluid one. It needs to be kept up and iterated. It should be approached with a mentality of constant awareness and persistent vigilance. Always question what the security implications involved in any system change are. Make certain that operating environments and default configurations are always optimizing security and working with sufficiently defensive software.
Happy Computing!
- How To Create a Kubernetes Cluster Using Kubeadm on Ubuntu 18.04 - June 24, 2021
- Nginx Server and Location Block Selection Algorithms: Overview - May 14, 2021
- Configuring an Iptables Firewall: Basic Rules and Commands - April 5, 2021
- How to Configure a Linux Service to Auto-Start After a Reboot or System Crash: Part 2 (Theoretical Explanations) - March 25, 2021
- How to Configure a Linux Service to Auto-Start After a Reboot or System Crash: Part 1 (Practical Examples) - March 24, 2021