

Container Technology and Docker
The idea of using containers for deployment in an application environment is not new. People have been using it for several years and with much success. With the help of containers, developers are able to isolate an application’s coding and configuration in an executable package. This prevents needless interference and hangups that would only slow down the user.
The use of container technology was further popularized by Docker. With Docker’s meticulous advertising, more and more people started to pick up on the strong benefits of using Linux containers for their applications. This was the beginning of the growing need for container and orchestration engines. You can learn more about how to work with Docker from our tutorial on how to clean up Docker resources and organize your servers.
An Introduction to Kubernetes: The Basics
Kubernetes takes things several steps farther than Docker. Launched in 2014 after Google put in years of work in its development, Kubernetes became the gold standard for its kind in the DevOps community. Also referred to as k8 or kube, Kubernetes is an open-source tool that allows users to better handle containers.
The goal of this powerful platform is to enable you to expertly manage containerized applications in a clustered environment. You can use the tool to coordinate containers, scale your services up and down, and schedule automated rollouts. However, the potential applications of the platform do not end there. It gives you full control over defining interactions within and among various containerized applications.
This guide will familiarize beginners with the basics of the Kubernetes platform. Further, we will discuss the basic architecture of k8, its critical components, and how you can use the tool to solve your deployment problems.
The Kubernetes Ecosystem
If you are working in a production environment with several applications, you will need to efficiently run hundreds of containers. This can prove to be a difficult task without the necessary tools. Kubernetes serves to make this job easier for developers. The best place to begin understanding the Kubernetes platform is its infrastructure. Its carefully constructed architecture enables it to provide its various functionalities. The best way to describe the construction of the Kubernetes tool is as a layered ecosystem. The foundation of the structure contains a shared network. This network is responsible for communicating between servers and tying the various machines to each other. This means that the configuration of all the components and workloads happens here, physically.
The relationships within the Kubernetes ecosystem follow a typical master-slave model. This means that one server is designated as the master server, whereas the rest of the connected machines are considered to be nodes. A master server paired with the nodes it controls constitutes a Kubernetes cluster.
The Kubernetes Model
The role of the master server in a cluster is similar to that of the brain within a human body. It is the gateway through which everything enters within the system. Furthermore, it assigns work to the worker nodes, coordinates communication between the individual components, and performs health monitoring functions. It is also responsible for exposing the API for the users as well as the clients.
The nodes, on the other hand, comprise a network of servers that perform the tasks assigned by the master. A worker node employs the use of local and external resources to run a workload and produce results. Since Kubernetes uses containers, each node is supplemented with a relevant container runtime. We will learn more about this component later. Once the order is delivered from the master to a node, the latter accepts it and either creates new containers or destroys them in response. This action, subsequently, determines the flow of traffic within the system from that point onwards.
The various components within the cluster make sure that your application remains in something called the desired state. You get to define the desired state for the execution of the containers in the given environment. The components of the Kubernetes architecture ensure that the actual state of the applications always corroborates with the desired state at all times.
If a user wants to communicate with the cluster, they have to do so through the API server. This communication can either be carried out directly or through clients and libraries. An extra client can submit a declarative plan in JSON or YAML which contains instructions pertaining to the creation and management of containers. The master receives the plan and executes it accordingly, depending upon the current state and requirements of the system.
The Kubernetes Master Server
The master server is the primary point of contact and communication with Kubernetes architecture. The various components of the master server work in collaboration to carry out a bunch of administrative tasks. These include analyzing and accepting user requests, scheduling containers, assigning workloads, authenticating clients, performing health check-ups, and scaling up and down as required. However, it is not necessary that the master consists of a single machine. In fact, many complex and sophisticated infrastructures use a group of selected servers for this purpose.
Components of the Kubernetes Master Server
Regardless of whether the following components are present in one machine or distributed across multiple servers, each serves a critical function:
etcd
etcd is a lightweight, distributed key-value database. It has a central position in the Kubernetes architecture. Developed by CoreOS, etcd acts as a storage position for its configuration data. Therefore, if a component needs to be configured or reconfigured, it can access the data from etcd through its node. This database also stores the state and the relevant metadata.
Values can be set and retrieved easily by providing an HTTP/JSON API. If the store is accessible to all of the machines in the ecosystem, there are no limits on how many master servers you configure etcd on.
kube-apiserver
The API server is arguably the most critical component in your master server. This server provides a connection between the health of the cluster and the instructions that are being sent out to the nodes. It is responsible for not only the management of the cluster but also for the configuration of the workloads. The API server verifies the etcd store and service details of containers as well.
The interface of the API server is referred to as the RESTful interface. This means that it welcomes interaction from a multitude of tools and libraries. If you wish to interact with a cluster from a local device, you can do so through a default client called kubectl.
kube-scheduler
We have previously talked about how the master is responsible for splitting and distributing the workloads. The scheduler component accounts for this function. It keeps track of the working load of every individual node. By doing so, it has updated tabs on how many resources are being utilized and how many are available at a given time. Thus, it determines which node has adequate resources free for use and assigns the workload accordingly. To make sure the scheduler does its job efficiently, you must configure the total capacity and allocated resources for existing workloads beforehand.
kube-controller-manager
The controller manager component is responsible for a number of different functions and tasks. As its name suggests, it is primarily responsible for managing the controllers that, in turn, manage the cluster state and other tasks in the ecosystem.
Take the replication controller, for example. This controller has to make sure that the number of copies deployed in the cluster is equal to the number of replicas that were defined in the pod. This data is in the etcd database. The controller manager interacts with the database through the API server to keep a check on the details of these operations. In case a change is detected by the controller manager, it springs into action. Its goal is to apply a solution that brings the system to the desired state. To do so, it may implement any relevant procedure, such as endpoint adjustment or scaling of operations.
cloud-controller-manager
The cloud controller manager is available to users as an add-on. If you are running your cluster on a cloud provider, you will find great use for this component. Regardless of which cloud provider you are using, this component will keep the internal constructs generic while bringing the rest of the features and APIs together. The cloud controller manager enables Kubernetes to extract necessary information from the cloud provider. This helps it adjust its cloud resources accordingly. Thus, it can make the necessary changes that are required to run a workload in the cluster.
Nodes in the Kubernetes Architecture
As mentioned before, the nodes are the servers that take commands from the master machine and run the containers. They can also configure container networking and interact with the components of the master server. But before they gain the capability to do so, certain requirements must be met.
Critical Components of Nodes
Following are some of the important components of nodes in a Kubernetes ecosystem:
Kubernetes control plane
Container Runtime
You must begin with the container runtime. This is an essential must-have for each, individual node. Its job is to start as well as manage the containers. Once the node receives the instructions from the master, it requires a container runtime to actually deploy the relevant containers. You can use an application such as Docker, but many have turned to rkt and runc in recent times as well.
kubelet
Each node is connected to the rest of the servers in the cluster with the help of kubelet. Kubelet is a small service that takes information to and from the control plane services. It is responsible for facilitating the node’s interaction with the etcd store as well, allowing it to enter new values and access configuration data.
On the other hand, the kubelet service has the responsibility to communicate with the components of the master server. It provides authentication to the cluster so that it may receive work in the shape of a manifest. The manifest contains details regarding the workload itself and the associated parameters that are critical to its deployment. Subsequently, the kubelet process must maintain the state of the work as it is carried out on the worker node. It does so by controlling the container runtime so as to create and destroy containers accordingly.
kube-proxy
Another component on the node servers is the kube-proxy. This is another small service that facilitates the availability of certain services to other components. It takes care of the subnetting and the networking, allowing the containers to communicate across the nodes on the cluster.
Objects and Workloads in the Kubernetes Architecture
The multiple layers in the architecture of Kubernetes add layers of abstraction over the container interface. The purpose of this additional abstraction is to add features like scaling and life cycle management to the platform. Because of these abstractions, the user does not interact directly with the containers. Instead, the Kubernetes object model provides primitives that the user can interact with. Let’s look at some of the objects that can be used to define a workload on Kubernetes:
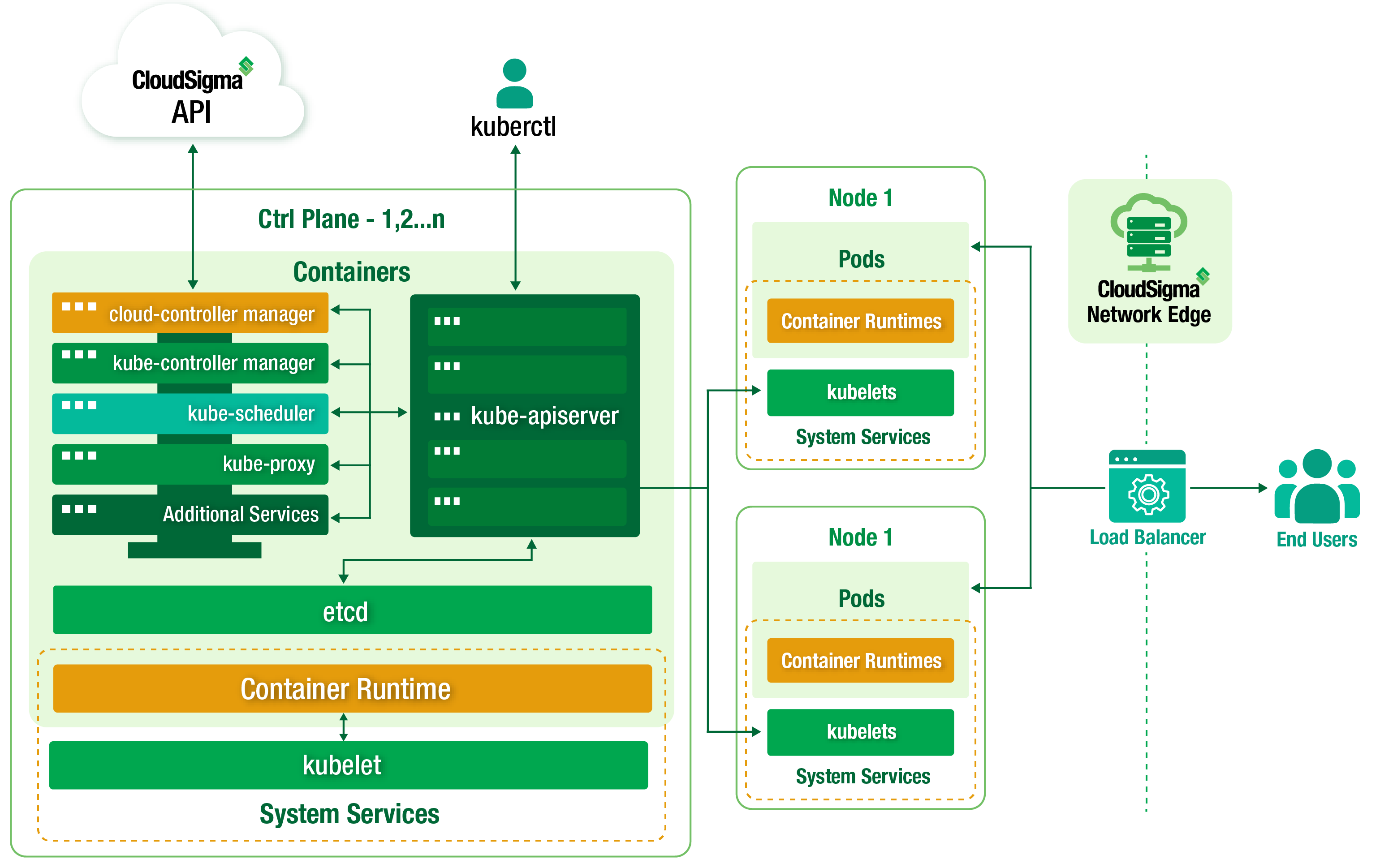
Architectural overview of Kubernetes
Pods
You can think of a pod as the basic functional unit on Kubernetes. Closely related containers have to be packaged together before they are assigned to a host. This package is referred to as a pod. Therefore, a pod usually contains one or more containers that are best controlled in the form of a single application. These coupled containers typically share a similar life cycle, operating environment, IP space, as well as volume. That is why you should make sure that they are scheduled on the same worker node and are managed as a single entity.
The composition of a pod usually involves the main container and associated helper containers. The former defines the general purpose of the workload. Whereas the latter is designed to supplement other closely related work. Helper containers may or not be present in a pod as per need. Although the presence of helper programs greatly facilitates the function of the main application. To understand this better, consider an example: think of a pod with two containers. The main container has the main application server. The helper container would contain a program that extracts files from the shared database when the external repository is modified.
Considering how basic of a functional unit a pod is in the Kubernetes ecosystem, users should avoid tinkering with them. Instead, they can interact with some of the higher level pods to implement tasks like lifecycle management and horizontal scaling.
Replication Controllers
Rather than managing individual pods, the user will generally work with replication sets. These are groups of replicated pods, each copy identical to the other. The identical replicas are created from pod templates and can be horizontally scaled. This scaling is performed by replication controllers and sets.
If you want to be able to define a pod template and manipulate parameters to implement the scaling of the replicas, you refer to the replication controller. Scaling is done by either increasing or decreasing the number of copies running at a given time. This is greatly beneficial in the case of load distribution management as it helps increase availability within the Kubernetes environment. The replication controller has an embedded copy of the template within the configuration. The embedded template very closely resembles the definitions of the original pod template. Thus, it can easily destroy copies and create new ones as needed.
It is also the responsibility of the replication controller to ensure that the number of pods in the cluster and the number of pods in its configuration are aligned. In case a pod fails to deploy or a host fails during the process, the controller will launch new pods to fulfill the requirements. If the user desires, they can also set up rolling updates for a group of new pods over a period of time. Doing so goes a long way in managing the burden on the availability of the apparition.
Replication Sets
Replication sets go one step beyond the capabilities of replication controllers. That is the reason they are taking the place of replication controllers in most spaces now. A replication set offers much more flexibility in regards to pod identification and replica selection. Although they do not have the ability to perform rolling updates. Therefore, they are mostly used in additional high-level units.
While you can interact with replication controllers and sets, there are more complex objects that you can work with instead. We will talk about some of them ahead.
Deployments
Deployments are a blessing when it comes to life cycle management and rolling updates. This object uses replication sets as a functional unit and can be manipulated directly to manage workloads. Without a deployment, the user would have to submit a full plan detailing the new replication controller when updating the application. With deployments, all you need to do is modify the configuration. The rest of the details, such as tracking history and adjustment of the replica sets, are left to Kubernetes to sort out automatically.
Stateful Sets
Stateful sets give the user an even finer degree of control. These are particularly useful in instances where special requirements are applicable. You will find these often when working with the likes of databases. The way that stateful sets work is that they assign number-based names to individual pods. These names are unique and act as a stable networking identifier for the given pod. For example, a data-oriented application must be able to access a set volume of data regardless of node rescheduling or pod deletion. Stateful sets will ensure the persistent volumes in these special cases.
You can use this high-level object for scaling purposes. Especially because it gives finer control over the implementation of the scaling, making the process more predictable. This is because the numbered identifiers are used to perform operations at this level.
Daemon Sets
Daemon sets, much like stateful sets, also operate in the vein of replication controllers. They typically run a copy of a given pod on each individual node, either throughout the cluster or through a specified subset. Daemon sets serve mainly maintenance purposes in the Kubernetes ecosystem. Since daemon sets are running basic services for the nodes and servers, pod scheduling restrictions typically do not apply to them. Thus, they may even access the master server, which is normally unavailable for pod scheduling.
Jobs
A job is a task-based object as opposed to a service. Jobs follow a workflow until the task completes. That is why they often perform single tasks or batch processing.
Cron Jobs
Cron jobs add the scheduling feature to the above-mentioned object. This allows you to schedule in advance jobs that you want to execute in the future. Linux users will already be aware of the cron daemons and what they entail.
Additional Critical Kubernetes Components
There are a bunch of other complex abstractions that exist in the Kubernetes architecture apart from the workloads and the servers. These components help the user gain a better degree of control over the management of their applications. We will introduce you to some of the commonly used additional Kubernetes components:
Services
As opposed to a task, a service generally refers to a long-running process. Services typically connect to each other via a network and can take and run requests. However, the definition that applies in Unix-like environments does not apply here as well.
In a Kubernetes environment, the term service defines a component that balances the internal load and acts as an ambassador for the pods. It will detect closely related pods and lump them as one as they serve a single function. This type-based categorization of the pods makes tracking and routing of the backend containers through a service much easier. The service component also becomes relevant when you need to provide an external client or application access to one or more pods in your system. In such a case, you will have to configure an internal service.
Each service has its own, stable IP address which keeps track of the service and makes it available. If a service must be available outside of the Kubernetes cluster, you can go either of two routes. The first one is the NodePort configuration. Here, you open up static ports of the external networking interface of each node. The consumers will enter the port and the internal cluster IP service will direct them towards the relevant pods automatically. The second route is the LoadBalancer. Here, you will create an external load balancer using the Kubernetes load balancer integration by the cloud provider. You need to have a cloud controller manager component to use this service type.
Volumes
Data sharing between containers has been an issue in most containerized architectures. The best that container runtimes have been able to do on their own is attaching some storage to a container. Kubernetes simplifies data sharing among containers with an abstraction called volumes.
With this abstraction, you can freely share data between the containers within a single pod until the pod is deleted. Failure of a container within the pod would not affect the shared data. The termination of the pod, however, would mean simultaneous destruction of the shared data.
Persistent Volumes
This abstraction counters the issue of permanent data destruction upon pod termination. Instead of being tied to the pod life cycle, the data remains persistent. Each data volume has a pre-configured reclamation policy which determines whether the volume persists until manually deleted or is destroyed immediately. Persistent volumes come in handy in case of node failures and lack of storage availability.
Labels
You can further simplify your Kubernetes management and organization with something called labels. A label is an organizational abstraction that can group certain Kubernetes objects together for easier implementation. For example, you can group together all the controller based objects or closely related services. Each semantic tag is delivered as a key-value pair and you have one entry for each key only. A name key is an identifier but you can assign other classifications and criteria to it as well.
Annotations
Similar to labels, annotations are also organizational abstractions. They allow you to add key-value information to objects for your convenience while routing and managing your application. Annotations are more flexible and unstructured than labels. That is why you can think of them as metadata that is not relevant to the selection of the object.
Conclusion
All in all, Kubernetes is an incredibly useful platform that is steadily gaining the ranks within the development community. Highly efficient and straightforward, the Kubernetes architecture offers great scaling capabilities, flexibility, and a ton of useful features. Not to mention, it is available entirely as an open-source tool. With some basic understanding of the fundamental building blocks and components of the ecosystem, you can facilitate your workloads on the platform as well.
Happy Computing!
- Removing Spaces in Python - March 24, 2023
- Is Kubernetes Right for Me? Choosing the Best Deployment Platform for your Business - March 10, 2023
- Cloud Provider of tomorrow - March 6, 2023
- SOLID: The First 5 Principles of Object-Oriented Design? - March 3, 2023
- Setting Up CSS and HTML for Your Website: A Tutorial - October 28, 2022