

With more than 330 million active users, Twitter is one of the top platforms where people like to share their thoughts. More importantly, twitter data can be used for a variety of purposes such as research, consumer insights, demographic insights and many more. In addition, twitter data insights are especially useful for businesses as they allow for the analysis of large amounts of data available online, which would be nearly impossible to investigate otherwise.
Similarly, in a previous blog post, we learned how to get a sample of tweets with Twitter API using Python. However, the amount of tweets we were able to collect with our previous Twitter program per keyword was around 200. With a big data tool like Apache Flume, we are able to extract real-time tweets. But using a normal account can only extract around 1% of the Twitter data. So, for the entire data, we would need an Enterprise account to access Twitter’s PowerTrack API. Moreover, the PowerTrack API provides customers with the ability to filter the full Twitter firehose, and therefore only receive the data that they or their customers are interested in.
Introduction to Flume
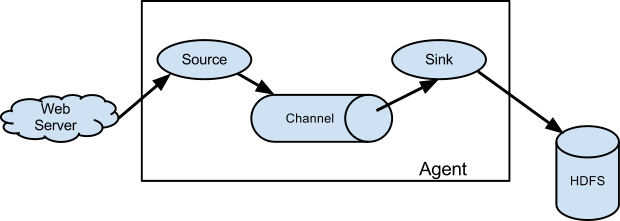
We are using Flume to access the real-time streaming data.
According to Apache.org, “Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. Also, it is robust and faults tolerant with tunable reliability mechanisms and many failovers and recovery mechanisms. It uses a simple extensible data model that allows for an online analytic application.”
 <groupId>org.twitter4j</groupId>
<groupId>org.twitter4j</groupId>
<artifactId>twitter4j-stream</artifactId>
<version>3.0.5</version>
</dependency>
New Dependency:
<dependency>
<groupId>org.twitter4j</groupId>
<artifactId>twitter4j-stream</artifactId>
<version>4.0.6</version>
<scope>compile</scope>
</dependency>
Firstly, in TwitterSourceConstants.java, I have defined the following new Strings. To be more specific, these are defined to get the values for the new filters we are adding from the Flume configuration file.
|
1 2 3 4 |
public static final String LANGUAGE_KEY = "language"; public static final String FOLLOW_IDS_KEY = "follow"; public static final String LOCATIONS_KEY = "locations"; public static final String COUNT_PREV_TWEETS_KEY = "count"; |
Now, moving onto TwitterSource.java, I am defining the following new variables.
|
1 2 3 4 |
private int count_prev_tweets; private String[] language; private long[] follow_ids; private double[][] locations; |
For these variables, we are getting the values from TwitterSourceConstants.java using Context.
|
1 2 3 4 |
String languageString = context.getString(TwitterSourceConstants.LANGUAGE_KEY, ""); String follow_ids_tmp = context.getString(TwitterSourceConstants.FOLLOW_IDS_KEY, ""); String locationstmp = context.getString(TwitterSourceConstants.LOCATIONS_KEY, ""); String count_prev = context.getString(TwitterSourceConstants.COUNT_PREV_TWEETS_KEY, ""); |
Next, we will be parsing the values that we have got in form of Strings, and converting them in the desired type.
Firstly, for language, we are converting it into an array of String.
|
1 2 3 4 5 6 7 8 |
if (languageString.trim().length() == 0) { language = new String[0]; } else { language = languageString.split(","); for (int i = 0; i < language.length; i++) { language[i] = language[i].trim(); } } |
Secondly, for follow_ids, we are converting it into an array of long.
|
1 2 3 4 5 6 7 8 9 |
if (follow_ids_tmp.length() == 0) { follow_ids = new long[0]; } else { follow_ids = new long[follow_ids_tmp.length()]; String follow_id_tmp[] = follow_ids_tmp.split(","); for (int i = 0; i < follow_id_tmp.length; i++) { follow_ids[i] = Long.parseLong(follow_id_tmp[i].trim()); } } |
Thirdly, for locations, we are converting it into a 2D array.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
if (locationstmp.trim().length() == 0) { locations = new double[0][0]; } else { double[][] list; //[-179.231086,13.182335,179.859685,71.434357] String[] locationsArr = locationstmp.split(","); list = new double[locationsArr.length / 2][2]; // 2D Array for (int i = 0; i < locationsArr.length; i++) { double[] tmp = new double[2]; tmp[0] = Double.parseDouble(locationsArr[i]); tmp[1] = Double.parseDouble(locationsArr[i + 1]); list[i / 2] = tmp; i += 1; } locations = list; } |
Next, for count_prev_tweets, we are converting it into an int value.
|
1 2 3 4 5 |
if (count_prev.trim().length() == 0) { count_prev_tweets = new Integer(0); } else { count_prev_tweets = Integer.parseInt(count_prev); } |
Now, along with the below-mentioned filtering of keywords, I am adding a few we just defined.
|
1 2 3 |
if (keywords.length > 0) { query.track(keywords); } |
Firstly, I am adding the filter for previous tweets:
|
1 2 3 |
if (count_prev_tweets > 0) { query.count(count_prev_tweets); } |
Secondly, I am adding the filter for languages:
|
1 2 3 |
if (language.length > 0) { query.language(language); } |
Thirdly, I am adding the filter of Twitter IDs:
|
1 2 3 |
if (follow_ids.length > 0) { query.follow(follow_ids); } |
Finally, I am adding the filter for geo-locations:
|
1 2 3 |
if (locations.length > 0) { query.locations(locations); } |
And now we can do maven clean install to get the output jar in the target folder.
Configuring Flume
First of all, remove the old version of twitter4j jars from $FLUME_HOME/lib and add the newer version of them which can be downloaded from Maven repositories. Next, delete flume-twitter-source-1.8.0 file from $FLUME_HOME/lib and copy your output jar to this folder.
After that, we are going to create a file, TwitterStream.properties, which we are placing in $FLUME_HOME. The content of the file would be.
Meanwhile, I am defining the agent’s source, channel, and sink here. Also, I am naming the agent TwitterAgent. As mentioned above, there are three components of the agent – Source, Channel, and Sink. So, we are naming our source Twitter, channel MemCh and sink HDFS.
|
1 2 3 |
TwitterAgent.sources = Twitter TwitterAgent.channels = MemCh TwitterAgent.sinks = HDFS |
Defining the source properties for TwitterAgent
Type of Twitter would be the fully classified class name in this case. And channels would be MemCh which would bind a connection between the source Twitter and channel MemCh. Next up, Consumer Key, Consumer Secret, Access Token and Access Token Secret can be obtained by creating an app on Twitter.
Moving on to our keywords – they are where we put the list of keywords which we want in our filtered tweets text, for example, Big Data, Data, Hadoop. We can put locations to filter tweets by geolocation, for instance. Also, we can use language to filter tweet by language, ‘en’ for English. Follow is for the list of Twitter IDs you would want the tweets from. And the Count is the number of previous tweets you’d want to retrieve before starting with the real-time data. However, the Count feature is only available for enterprise accounts on Twitter.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
TwitterAgent.sources.Twitter.type = com.cloudsigma.flume.twitter.TwitterSource TwitterAgent.sources.Twitter.channels = MemCh TwitterAgent.sources.Twitter.consumerKey = <<consumer key>> TwitterAgent.sources.Twitter.consumerSecret = <<consumer secret>> TwitterAgent.sources.Twitter.accessToken = <<access token>> TwitterAgent.sources.Twitter.accessTokenSecret = <<access token secret>> TwitterAgent.sources.Twitter.keywords = big data, data, hadoop TwitterAgent.sources.Twitter.locations = 8.5241,76.9366,28.7041,77.1025 TwitterAgent.sources.Twitter.language = en TwitterAgent.sources.Twitter.follow = 16134540,288500051 #TwitterAgent.sources.Twitter.count = 1000 |
Defining the sink properties for HDFS
The channel that we have set for HDFS sink is MemCh. This would connect our source with sink. Here, the type of sink is hdfs. The path for the same is flume/Twitter/ on my HDFS. Inside those folders, there would be data partitioned into multiple folders based on when that data was acquired. I am listing down the definition of other properties from Flume’s documentation below with their default values listed in the 2nd column as well:
| hdfs.rollInterval | 30 | Number of seconds to wait before rolling current file (0 = never roll based on time interval) |
| hdfs.rollSize | 1024 | File size to trigger roll, in bytes (0: never roll based on file size) |
| hdfs.rollCount | 10 | Number of events written to file before it rolled (0 = never roll based on a number of events) |
| hdfs.batchSize | 100 | number of events written to file before it is flushed to HDFS |
| hdfs.fileType | SequenceFile | File format: currently SequenceFile, DataStream or CompressedStream (1)DataStream will not compress output file and please don’t set codeC (2)CompressedStream requires set hdfs.codeC with an available codeC |
| hdfs.writeFormat | Writable | Format for sequence file records. One of Text or Writable. Set to Text before creating data files with Flume, otherwise, those files cannot be read by either Apache Impala (incubating) or Apache Hive. |
|
1 2 3 4 5 6 7 8 9 |
TwitterAgent.sinks.HDFS.channel = MemCh TwitterAgent.sinks.HDFS.type = hdfs TwitterAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/flume/Twitter/day_key=%Y%m%d/ TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream TwitterAgent.sinks.HDFS.hdfs.writeformat=Text TwitterAgent.sinks.HDFS.hdfs.batchSize=1000 TwitterAgent.sinks.HDFS.hdfs.rollSize=0 TwitterAgent.sinks.HDFS.hdfs.rollCount=10000 TwitterAgent.sinks.HDFS.hdfs.rollInterval=600 |
Defining the channel properties for Memory Channel
The type of MemCh is memory. I am listing the definition of the properties from Flume’s documentation below with their default values listed in the 2nd column as follows:
| capacity | 100 | The maximum number of events stored in the channel |
| transactionCapacity | 100 | The maximum number of events the channel will take from a source or give to a sink per transaction |
|
1 2 3 |
TwitterAgent.channels.MemCh.type = memory TwitterAgent.channels.MemCh.capacity = 10000 TwitterAgent.channels.MemCh.transactionCapacity = 1000 |
Now, we can execute the following command in the $FLUME_HOME directory to start the ingestion. On another note, you can add the bin directory of $FLUME_HOME to directly access the commands anywhere. Following is the description of the parameters of this command.
- conf-file : The flume configuration file where we have configured the source, channel, sink and the related properties.
- name : Name of the Agent. In this case, TwitterAgent
- conf : Configuration directory of the flume. Generally, $FLUME_HOME/conf
- Dflume.root.logger=INFO,console : It writes the logs to console
|
1 |
./bin/flume-ng agent -f TwitterStream.properties --name TwitterAgent --conf $FLUME_HOME/conf -Dflume.root.logger=INFO,console |
In addition, the modified implementation can be found here. And the configuration file and the jar can be found in the ‘output’ folder on the same link.
- Removing Spaces in Python - March 24, 2023
- Is Kubernetes Right for Me? Choosing the Best Deployment Platform for your Business - March 10, 2023
- Cloud Provider of tomorrow - March 6, 2023
- SOLID: The First 5 Principles of Object-Oriented Design? - March 3, 2023
- Setting Up CSS and HTML for Your Website: A Tutorial - October 28, 2022