
一个 CSV 文件是一个以表格格式存储数据的纯文本文件。在大多数情况下,CSV 文件使用逗号 (,) 作为分隔符,因此得名 CSV(逗号分隔值)。它’在需要考虑数据兼容性的情况下被使用,因为 CSV 可以使用任何文本编辑器、电子表格应用程序和其他专业工具打开。事实上,许多编程语言都提供了对 CSV 的内置支持。
在本指南中,我们将学习如何在示例 Node.js 应用中使用 CSV。
Node.js 中的 CSV
Node.js 是一个开源且跨平台的 JavaScript 运行时环境。它已成为最受欢迎的后端之一,为互联网上的众多 Web 服务提供支持。甚至像 Netflix 和 Uber 这样的大公司也使用 Node.js 来支持其服务。
Node.js 还有许多可部署的模块,用于为项目添加额外功能。说到 CSV,有许多可用的模块,例如 node-csv, fast-csv、以及 papaparse 等。
正如指南标题所示,我们将使用 node-csv 通过 Node.js 流来读取 CSV 文件。我们还将演示如何处理解析后的数据,例如将数据传输到 SQLite 数据库中。
前提条件
-
要执行本指南中演示的步骤,您需要以下组件:
-
配置妥当的 Linux 系统。了解更多关于 在 CloudSigma 上安装和配置 Ubuntu 云服务器.
-
具有 sudo 权限的非 root 用户访问权限。请参阅 使用 sudoers 管理 sudo 权限.
-
合适的文本编辑器,例如 Brackets, VS Code, Sublime Text, Vim/NeoVim 等。
-
其他软件:
-
Node.js LTS
-
SQLite
-
步骤 1 – 安装必要软件
在本指南中,我创建了一个运行 Ubuntu 22.04 LTS 的轻量级服务器(通过 SSH 连接):
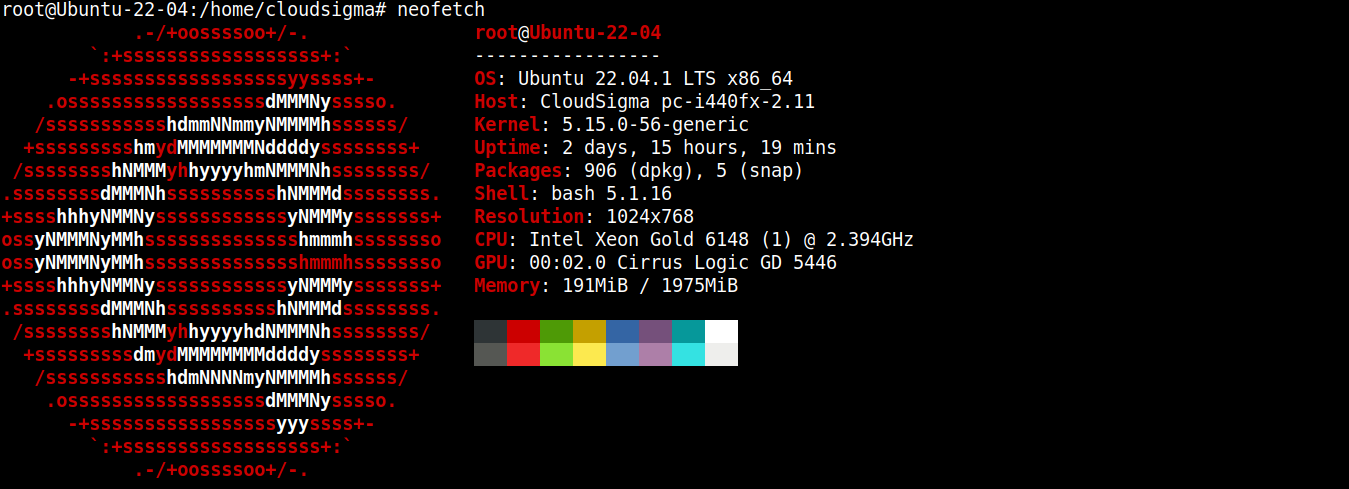
现在,我们将在其上安装 Node.js 和 SQLite。
-
安装 Node.js LTS
Node.js 可以直接从官方 Ubuntu 软件包仓库中获取。然而,它’不是最新版本。这就是为什么我们要依赖第三方仓库(Nodesource)来获取最新的 Node.js 软件包。
添加 Node.js LTS 的仓库:
|
1 |
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash - |
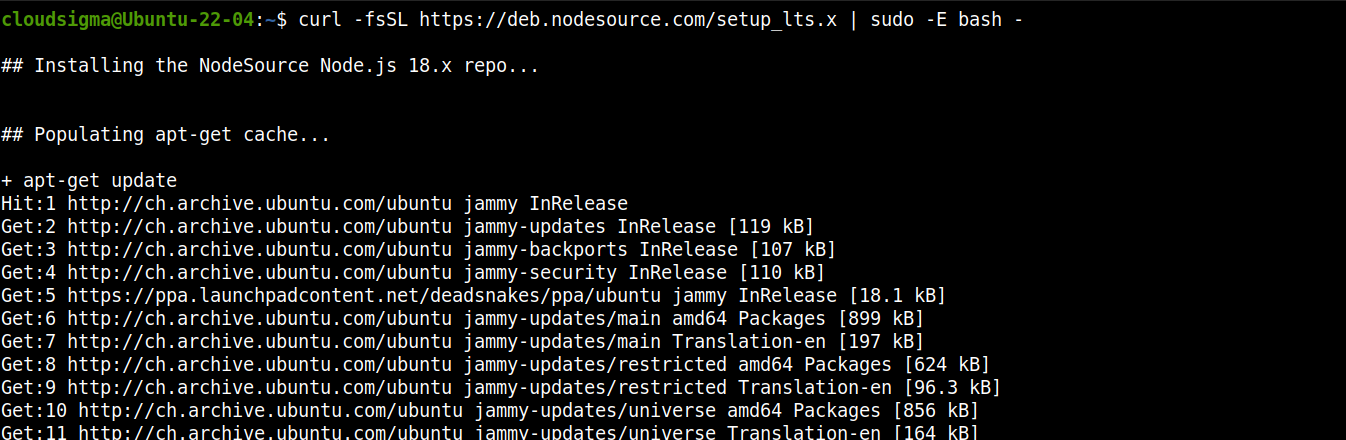
现在,安装 Node.js LTS:
|
1 |
sudo apt install nodejs -y |

-
安装 SQLite
我们将直接从 Ubuntu 软件包仓库安装 SQLite。运行以下命令:
|
1 |
sudo apt install sqlite3 -y |

步骤 2 – 项目目录设置
在本节中,我们将为我们的项目准备一个专用目录。它将托管所有项目文件以及其他模块。
创建一个新目录:
|
1 |
mkdir -pv csv_practice |
进入该目录:
|
1 |
cd csv_practice/ |
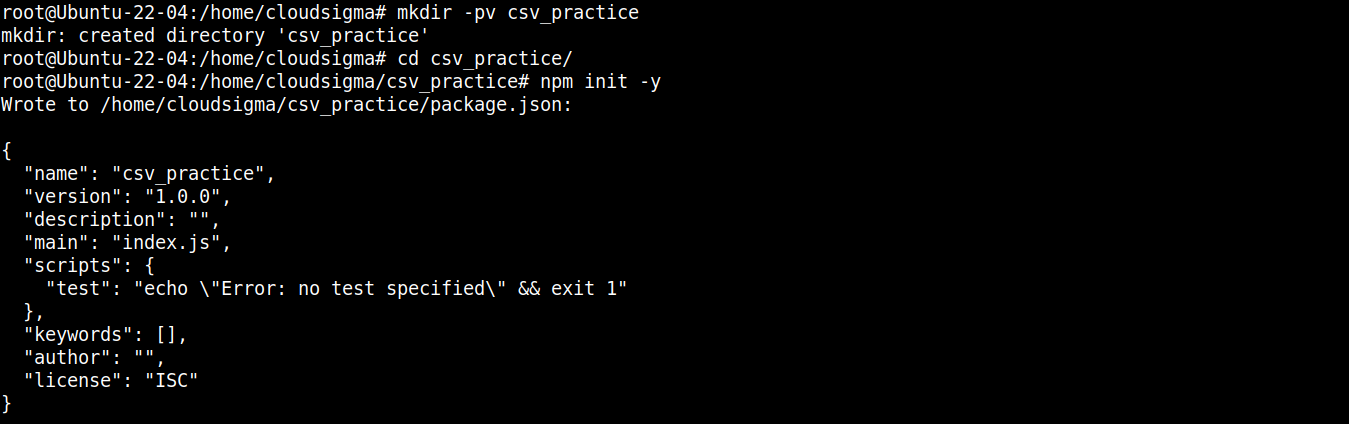
接下来,运行以下命令将该目录声明为 npm 项目:
|
1 |
npm init -y |
初始化项目文件夹后,我们就可以开始安装必要的包和模块。首先,我们将安装 node-csv:
|
1 |
npm install csv |

node-csv 模块实际上是其他几个模块的集合:csv-generate, csv-parse(解析 CSV 文件)、csv-stringify(将数据写入 CSV)以及 stream-transform.
接下来,我们需要用于与 SQLite 通信的模块。以下命令将安装 node-sqlite3 模块:
|
1 |
npm install sqlite3 |

我们项目所需的组件是一个 CSV 文件。为了演示目的,我们将使用新西兰移民 CSV 文件:
|
1 |
wget https://www.stats.govt.nz/assets/Uploads/International-migration/International-migration-September-2021-Infoshare-tables/Download-data/international-migration-September-2021-estimated-migration-by-age-and-sex-csv.csv -O migration_data.csv |
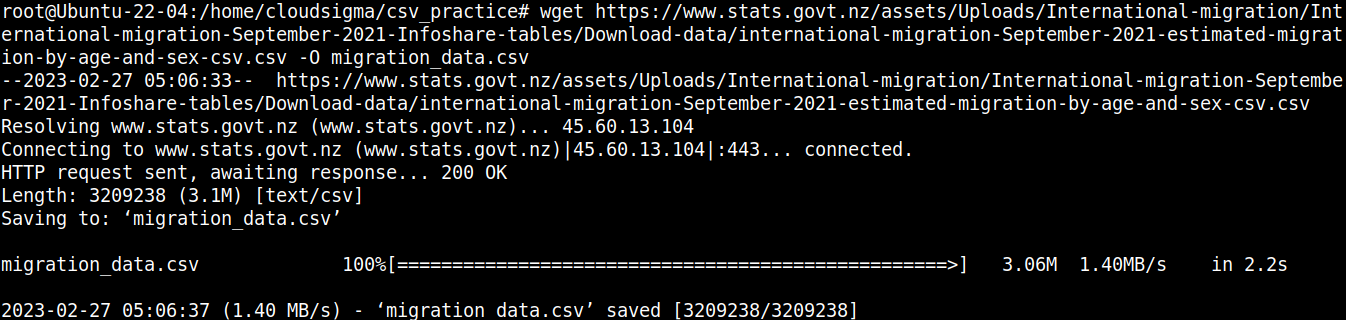
让我们快速查看一下文件的内容:
|
1 |
cat migration_data.csv | less |
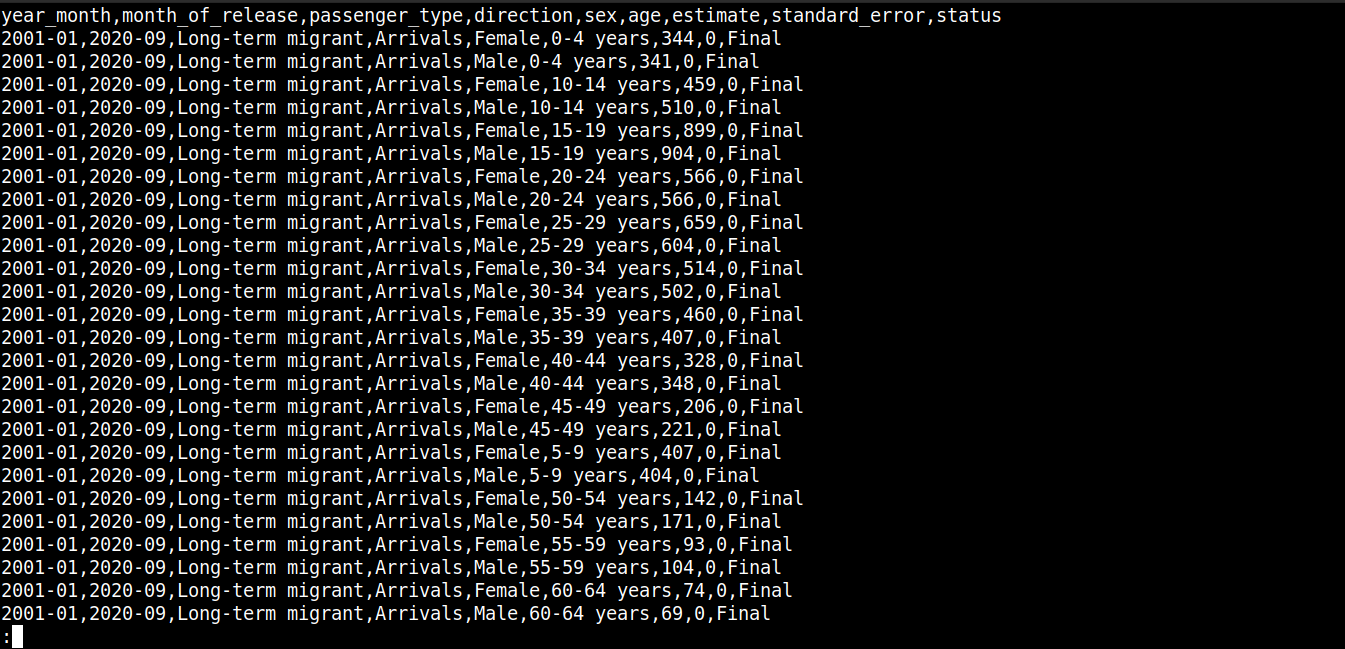
在这里,
-
第一行描述了列名。
-
随后的行包含这些字段的值。
-
每一行由换行符 (\n) 分隔。
-
每个数据点由逗号 (,) 分隔。
然而,CSV 并不局限于使用逗号作为分隔符。其他常见的分隔符包括冒号 (:)、分号 (;) 和制表符 (\td)。
步骤 3 – 读取 CSV
在本节中,我们将演示如何实现一个从 CSV 文件中读取并解析数据的示例程序。
创建一个新的 JavaScript 文件:
|
1 |
touch read_csv.js |
在您最喜欢的文本编辑器中打开该文件:
|
1 |
nano read_csv.js |
首先,我们将导入 fs 和 csv-parse 模块:
|
1 2 |
const fs = require("fs"); const { parse } = require("csv-parse"); |
在这里,
-
首先, fs 变量被赋值为 fs 对象,该对象在导入模块时返回 Node.js 的 require() 方法。
-
接下来,从 require() 方法返回的对象中提取 parse 方法到 parse 变量中,使用的是 解构语法.
接下来,我们将添加代码来读取 CSV 文件:
|
1 2 3 4 5 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) |
在这里,
-
我们正在调用 createReadStream()(来自 fs 模块),并将我们要读取的 CSV 文件作为参数传递。然后,它通过将大文件拆分为较小的块来创建一个可读流。
-
创建流之后, pipe() 方法将流数据的块转发到另一个流。这个新流是在调用 parse() 方法(来自 csv-模块)时创建的.
-
The csv- 模块 部署了一个可读/可写的转换流,该流接收数据块并将其转换为另一种形式。
-
The parse() 方法接受带有属性的对象。该对象进一步处理解析后的数据。在这里,该对象接收以下属性:
-
delimiter:用于分隔值的定界符。在我们的目标 CSV 中,它是逗号 (,)。
-
from_line:解析器开始解析的行数。给定值为 2 时,解析器将跳过第 1 行并从第 2 行开始。通过这种安排,我们可以避免将列名整合到解析的数据中。
-
接下来,我们将使用 Node.js 中的 on() 方法来附加一个流事件:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
在这里,
-
在触发特定事件时,流事件允许方法消费一个数据块。
-
当由 parse() 方法解析的数据准备好被消费时,它会触发 data 事件。
-
为了访问数据,我们向 on() 方法传递一个带有 row 参数的回调函数。
-
row 参数是数组形式的数据块(解析的结果)。
-
最后,使用 console.log().
为了完成程序,我们将添加额外的流事件来处理错误,并在 CSV 文件中的所有数据都被消费时打印一条成功消息。如下更新代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
这里,
-
当 CSV 文件中的所有数据都被消耗完时,会触发 end 事件。这会导致调用 console.log() 方法,该方法会打印一条成功消息。
-
在解析 CSV 数据时如果遇到错误,会触发 error 事件。这会导致调用 console.log() 方法,该方法会打印一条错误消息。
最终的代码应该像这样:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const fs = require("fs"); const { parse } = require("csv-parse"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
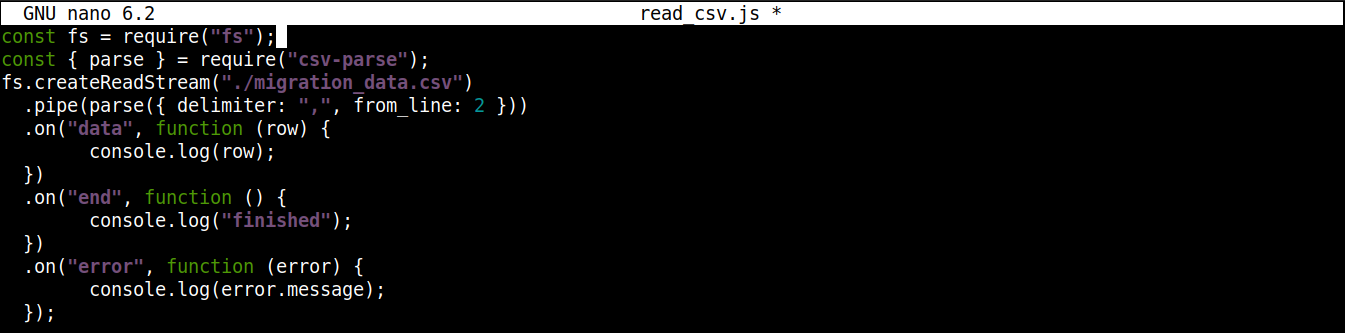
保存文件并关闭编辑器。我们现在准备好执行该程序了。使用 Node.js 运行它:
|
1 |
node read_csv.js |
输出应该类似于以下内容:

请注意,数据是被消耗、转换并打印在控制台上的。由于这是一个持续的过程,它看起来就像是在下载数据,而不是一次性打印出所有输出。
步骤 4 – 将 CSV 数据传输到数据库
到目前为止,我们已经学习了如何使用 node-csv 来解析 CSV 文件。本节将演示如何将解析后的数据传输到数据库(SQLite)中。
创建一个新的 JavaScript 文件以与数据库进行交互:
|
1 |
touch csv-to-sqlite3.js |
现在,在文本编辑器中打开该文件:
|
1 |
nano csv-to-sqlite3.js |
![]()
我们将使用以下代码开始我们的程序:
|
1 2 3 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; |

这里,
-
在第一行中,我们正在导入 fs 模块。
-
在第三行中,变量 filepath 包含了 SQLite 数据库的路径。
-
此时,数据库还不存在。然而,当使用 node-sqlite3.
接下来,添加以下行以建立与 SQLite 数据库的连接:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } console.log("Connected to the database successfully"); }); return db; } } |
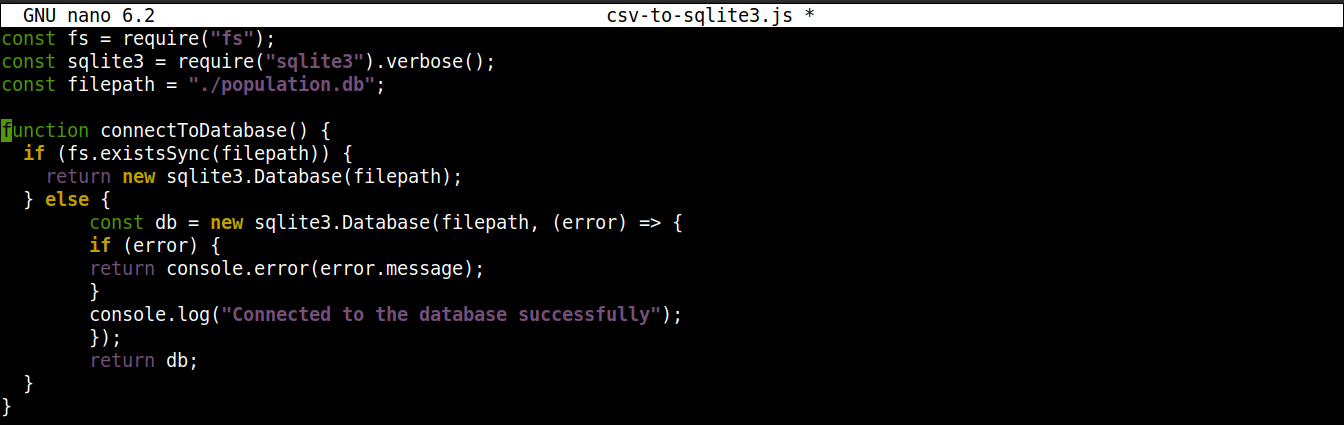
在这里,
-
方法 connectoToDatabase() 建立了与数据库的连接。
-
在 connectToDatabase() 中,我们正在调用 existsSync() 方法,该方法来自 if 语句中的 fs 模块。if 语句检查指定位置中是否存在该数据库。
-
如果条件评估为 true,那么 Database() 类,属于 node-sqlite3 模块。一旦建立连接,该函数将返回一个对象并退出。
-
如果条件评估为 false(数据库不存在),那么执行将跳转到 else 块。在其中, Database() 类将使用两个参数进行初始化:数据库文件的路径和一个回调函数。
-
基本上,如果数据库不存在,它将被创建。但是,如果在创建过程中发生任何错误,它将设置 error 对象并打印错误消息。
接下来,我们将介绍在数据库不存在时创建表的代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } createTable(db); console.log("Connected to the database successfully"); }); return db; } } function createTable(db) { db.exec(` CREATE TABLE migration ( year_month VARCHAR(10), month_of_release VARCHAR(10), passenger_type VARCHAR(50), direction VARCHAR(20), sex VARCHAR(10), age VARCHAR(50), estimate INT ) `); } module.exports = connectToDatabase(); |
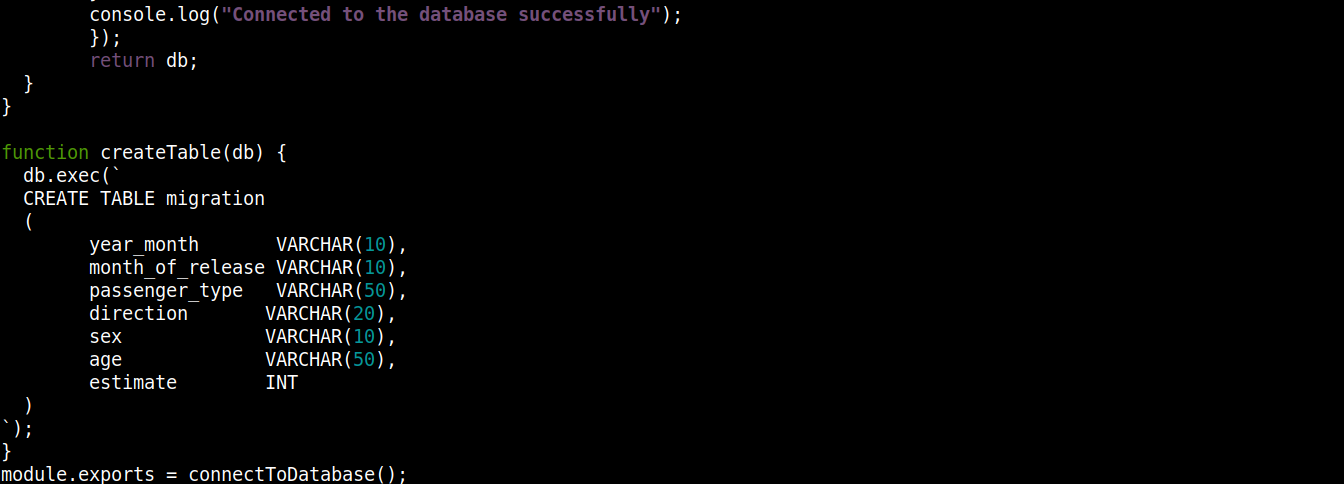
在这里,
-
The connectToDatabase() 调用了 createTable() 函数,该函数接受存储在 db 中的对象作为参数。
-
在 connectToDatabase() 之外,我们定义了 createTable() 方法,该方法接受连接对象 db 作为参数。
-
The exec() 方法在 db 上接受一个 SQL 语句作为参数。在此 SQL 语句中,我们定义了创建表 migration,它包含 7 列,每一列对应于 migration_data.csv 文件中的列标题。
-
最后,我们正在调用 connectToDatabase() 方法并导出它返回的连接对象,以便我们可以在其他文件中使用它。
保存文件并关闭编辑器。
接下来,我们将创建另一个程序来将解析后的数据插入到数据库中:
|
1 |
nano insert_data.js |
在以下文件中输入以下代码 insert_data.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const fs = require("fs"); const { parse } = require("csv-parse"); const db = require("./csv-to-sqlite3"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { db.serialize(function () { db.run( `INSERT INTO migration VALUES (?, ?, ? , ?, ?, ?, ?)`, [row[0], row[1], row[2], row[3], row[4], row[5], row[6]], function (error) { if (error) { return console.log(error.message); } console.log(`Row inserted, ID: ${this.lastID}`); } ); }); }); |
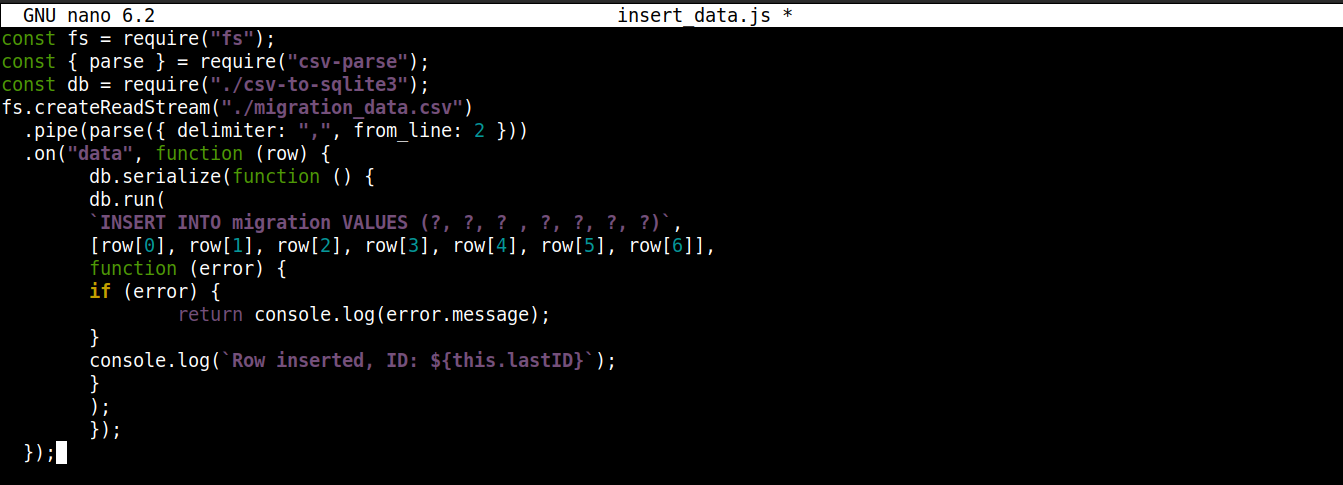
在这里,
-
我们将从 csv-to-sqlite3.js 获取的连接对象存储在变量 db.
-
在 data 事件回调(附加到 fs 模块流)中,我们正在调用 serialize() 方法(在连接对象上)。它确保一个 SQL 语句在下一个语句开始执行之前完成执行,从而防止数据库竞争条件(系统同时运行竞争操作)。
-
该 serialize() 接受三个参数:
-
第一个参数是 SQL 语句。
-
第二个参数是一个数组。
-
第三个参数是一个回调函数,在数据成功或失败插入数据库时运行。
-
我们已经准备好执行该程序。运行 insert_data.js ,使用 Node.js:
|
1 |
node insert_data.js |
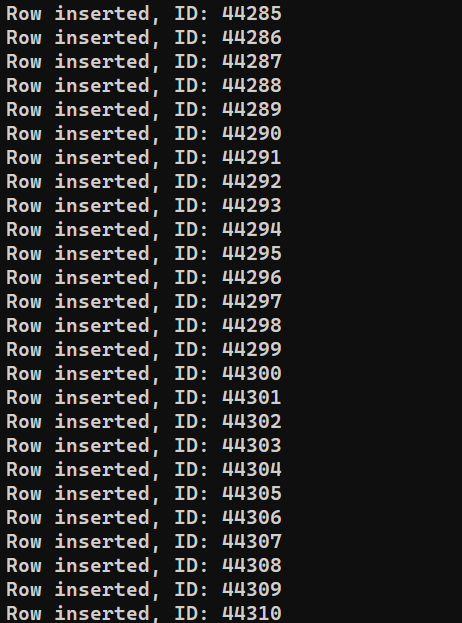
根据系统的性能,该过程可能需要一些时间才能完成。但是,完成后,输出应该类似于以下内容:
第 5 步 – 将数据写入 CSV
在上一节之后,我们得到了一个数据库,其中包含我们从 migration_data.csv 中解析的所有记录。在本节中,我们将从数据库中读取数据并将其写入一个单独的 CSV 文件中。
创建一个新的 JavaScript 文件来存储该程序:
|
1 |
nano write_csv.js |
首先,添加以下行以导入 fs 和 csv-stringify 以及来自 csv-to-sqlite3.js:
|
1 2 3 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); |
接下来,我们将添加一个变量,其中包含要写入的 CSV 文件的名称以及一个可写流:
|
1 2 3 4 5 6 7 8 9 10 11 |
const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; |
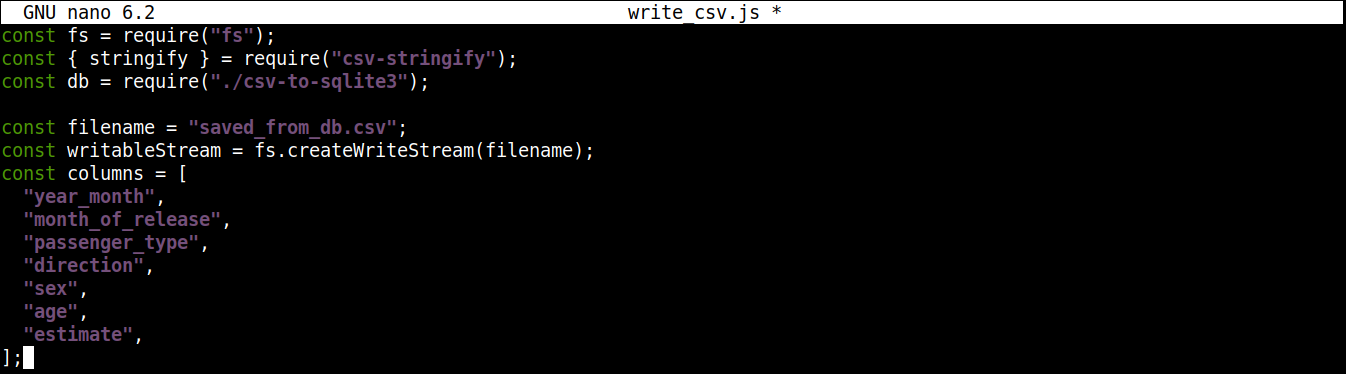
在这里,
-
该 createWriteStream() 方法接受要写入的文件名作为参数。我们将该文件命名为 saved_from_db.csv.
-
该 column 变量存储一个数组,其中包含 CSV 数据的所有表头名称。
接下来,添加以下几行代码以从数据库中读取数据并将其写入 saved_from_db.csv:
|
1 2 3 4 5 6 7 8 9 10 11 |
const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("finished writing to CSV"); |
在这里,
-
我们正在调用 stringify() 方法,并将一个对象作为参数。它会产生一个转换流,将数据从对象转换为 CSV 格式。传递给 stringify() 的对象有两个属性:
-
header:接受一个布尔值。如果值为 true,则会生成表头。
-
columns:接受一个数组,其中包含要在 CSV 文件第一行中写入的列名,如果 header 为 true.
-
-
该 each() 方法来自 csv-to-sqlite3 连接对象,调用时传入两个参数:SQL 语句(从数据库读取数据)和回调函数(处理成功/错误)。
-
在 each(), 的每次迭代中,pipe()(来自 stringifier 流)开始将数据分块发送到可写流 writableStream。然后,每块数据都会被写入 saved_from_db.csv.
-
当所有数据都写入 CSV 文件后,控制台屏幕上会打印一条成功消息。
最终的代码应该像这样:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("finished writing to CSV"); |
Save the file and close the editor. We can now run the program using Node.js:
|
1 |
node write_csv.js |
To confirm whether the data was successfully exported, check the content of saved_from_db.csv:
|
1 |
cat saved_from_db.csv | less |
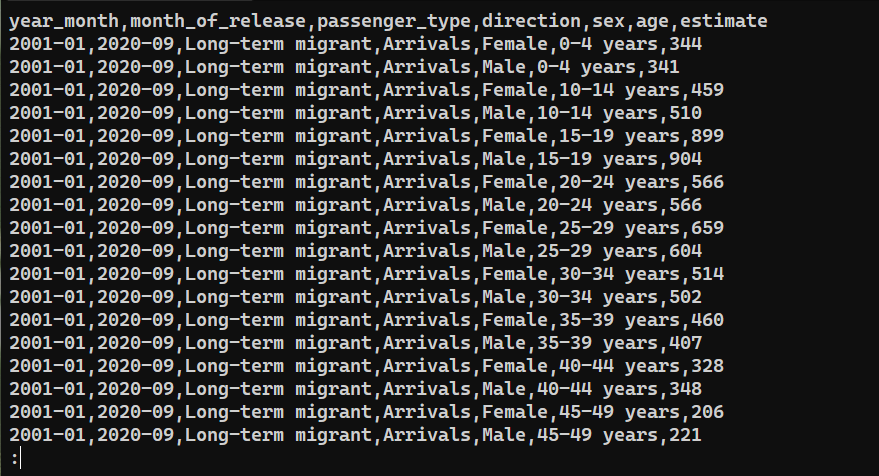
Final Thoughts
In this guide, we demonstrated working with CSV files in Node.js using node-csv and node-sqlite3 modules. We created multiple programs to achieve various tasks, for example, parsing data from CSV, pushing the data into an SQLite database, and writing data to a new CSV file.
This guide demonstrates only a small portion of the capability of the node-csv module. Learn more about all its features at CSV Project. To learn more about node-sqlite3, check out the official documentation on GitHub. Another module worth mentioning is event-stream to simplify working with streams.
Interested in growing your Node.js project further? Here are some Node.js tutorials that you should check out:
-
How to Deploy a Node.js (Express.js) App with Docker on Ubuntu 20.04
-
Setting up Node.js Applications: How to Perform Production Tasks on Ubuntu 20.04 with Node.js
Happy Computing!
评论
暂无评论。发表第一条评论吧。