
Egy CSV fájl egy egyszerű szöveges fájl, amely táblázatos formátumban tárolja az adatokat. A legtöbb esetben a CSV-fájlok vesszőt (,) használnak határolóként, innen ered a CSV (Comma Separated Values - vesszővel elválasztott értékek) név. Olyan helyzetekben használják, amikor az adatkompatibilitás fontos szempont, mivel a CSV-fájlok bármilyen szövegszerkesztővel, táblázatkezelő alkalmazással és egyéb speciális eszközökkel megnyithatók. Valójában számos programozási nyelv kínál beépített támogatást a CSV-hez.
Ebben az útmutatóban megtanuljuk a CSV használatát egy minta Node.js alkalmazásban.
CSV a Node.js-ben
A Node.js egy nyílt forráskódú és platformfüggetlen JavaScript futtatókörnyezet. Az egyik legnépszerűbb háttérrendszerré (backend) vált, amely számos webszolgáltatást működtet az interneten. Még az olyan nagyvállalatok is, mint a Netflix és az Uber, a Node.js-t használják szolgáltatásaik működtetésére.
A Node.js számos olyan modullal is rendelkezik, amelyek telepíthetők a projektek extra funkciókkal való bővítésére. Ha a CSV-ről van szó, számos modul áll rendelkezésre, például a node-csv, fast-csv, és papaparse stb.
Ahogy az útmutató címe is sugallja, a node-csv modult fogjuk használni a CSV-fájlok olvasására Node.js streamek segítségével. Bemutatjuk az elemzett adatokkal való munkát is, például az adatok átvitelét egy SQLite adatbázisba.
Előfeltételek
-
Az ebben az útmutatóban bemutatott lépések végrehajtásához a következő összetevőkre lesz szüksége:
-
Egy megfelelően konfigurált Linux rendszer. Tudjon meg többet az Ubuntu felhőszerver telepítéséről és konfigurálásáról a CloudSigma-n.
-
Hozzáférés egy nem-root felhasználóhoz sudo jogosultsággal. Tekintse meg a sudo jogosultságok kezelése a sudoers segítségével.
-
Egy megfelelő szövegszerkesztő, például a Brackets, VS Code, Sublime Text, Vim/NeoVim, stb.
-
Egyéb szoftverek:
-
Node.js LTS
-
SQLite
-
1. lépés – A szükséges szoftverek telepítése
Ehhez az útmutatóhoz egy Ubuntu 22.04 LTS-t futtató, könnyűsúlyú szervert hoztam létre (SSH-n keresztül csatlakozva):
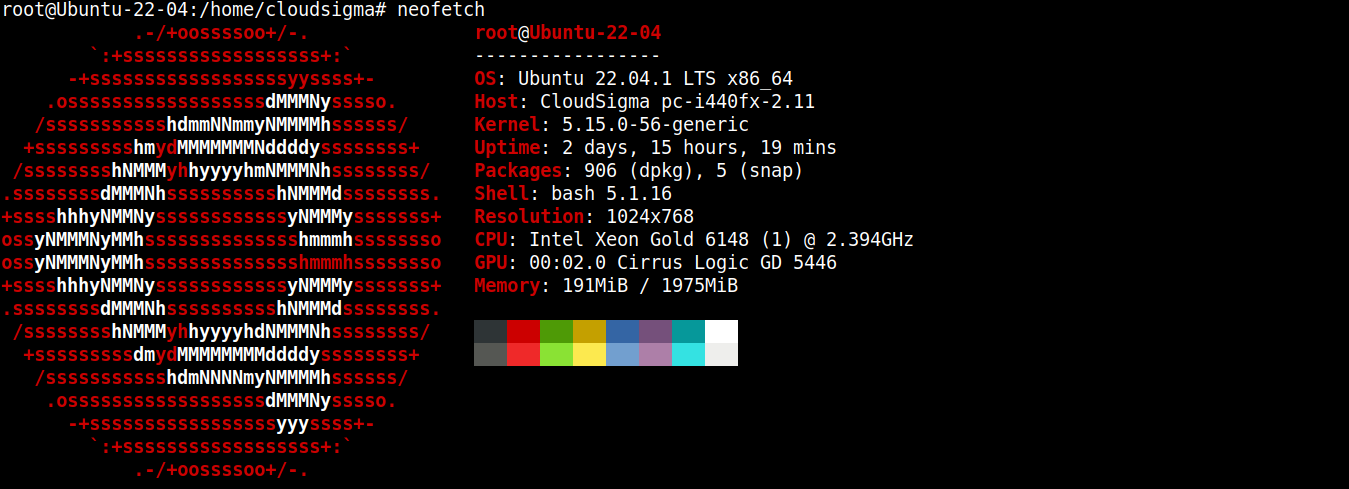
Most telepíteni fogjuk rá a Node.js-t és az SQLite-ot.
-
A Node.js LTS telepítése
A Node.js közvetlenül elérhető a hivatalos Ubuntu csomagtárolókból. Ez azonban nem a legfrissebb verzió. Ezért egy harmadik féltől származó tárolóra (Nodesource) fogunk támaszkodni a legújabb Node.js csomagok beszerzéséhez.
Adja hozzá a Node.js LTS tárolóját:
|
1 |
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash - |
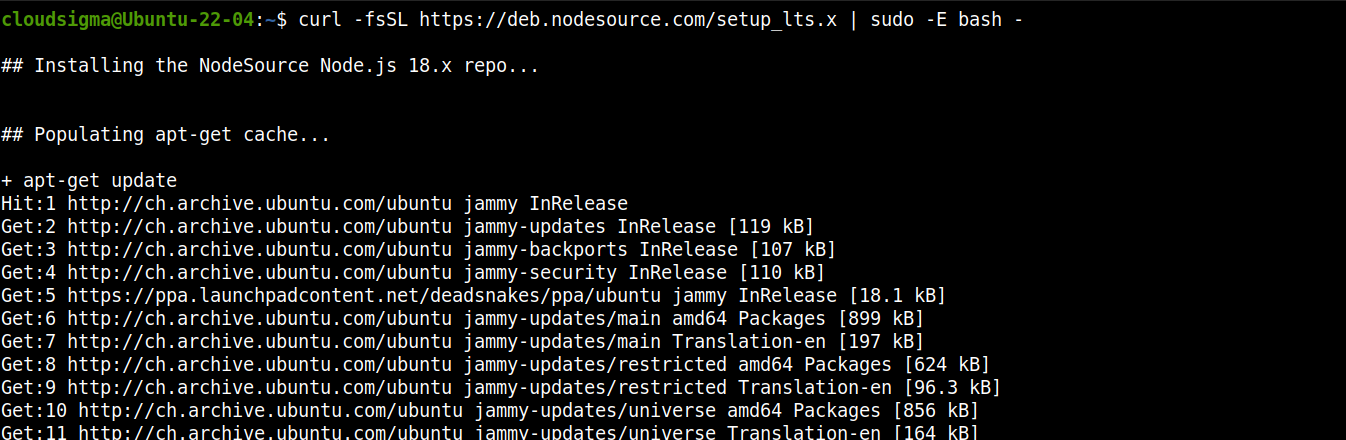
Most telepítse a Node.js LTS-t:
|
1 |
sudo apt install nodejs -y |

-
Az SQLite telepítése
Az SQLite-ot közvetlenül az Ubuntu csomagtárolókból fogjuk telepíteni. Futtassa a következő parancsokat:
|
1 |
sudo apt install sqlite3 -y |

2. lépés – A projektkönyvtár beállítása
Ebben a szakaszban egy külön könyvtárat készítünk elő a projektünk számára. Ez fogja tárolni az összes projektfájlt a további modulokkal együtt.
Hozzon létre egy új könyvtárat:
|
1 |
mkdir -pv csv_practice |
Lépjen be a könyvtárba:
|
1 |
cd csv_practice/ |
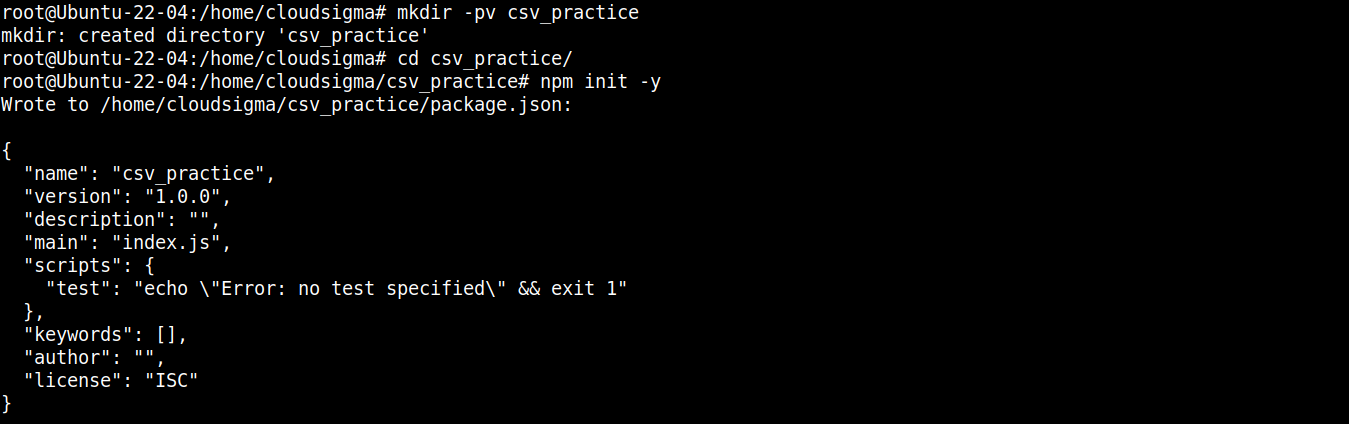
Ezután futtassa a következő parancsot, hogy a könyvtárat npm projektként deklarálja:
|
1 |
npm init -y |
Miután a projektmappa inicializálása megtörtént, elkezdhetjük a szükséges csomagok és modulok telepítését. Először a node-csv:
|
1 |
npm install csv |

A node-csv modul valójában több más modul gyűjteménye: csv-generate, csv-parse (CSV-fájlok elemzése), csv-stringify (adatok írása CSV-be), és stream-transform.
Ezután szükségünk van az SQLite-tal való kommunikációhoz szükséges modulra. A következő parancs telepíti a node-sqlite3 modult:
|
1 |
npm install sqlite3 |

A projektünkhöz szükséges összetevő egy CSV-fájl. Bemutató céljából az új-zélandi migrációs CSV-fájlt fogjuk használni:
|
1 |
wget https://www.stats.govt.nz/assets/Uploads/International-migration/International-migration-September-2021-Infoshare-tables/Download-data/international-migration-September-2021-estimated-migration-by-age-and-sex-csv.csv -O migration_data.csv |
Vessünk egy gyors pillantást a fájl tartalmára:
|
1 |
cat migration_data.csv | less |
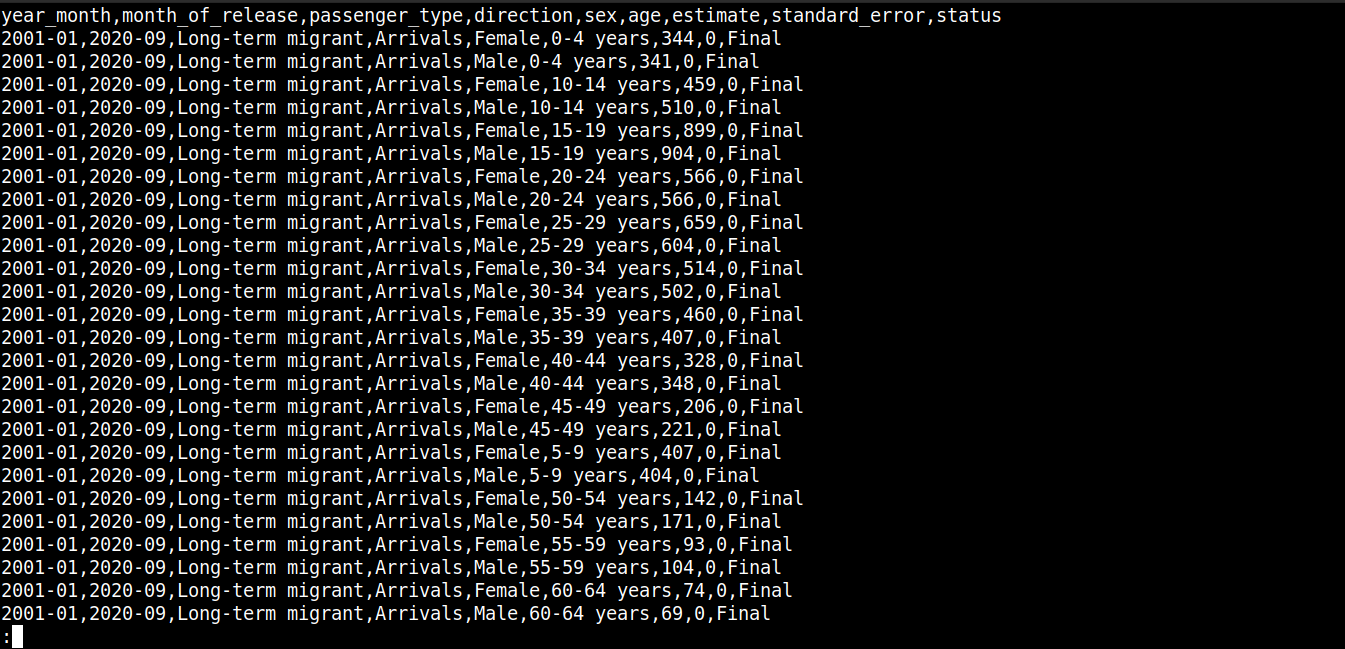
Itt,
-
Az első sor az oszlopneveket írja le.
-
A következő sorok tartalmazzák ezen mezők értékeit.
-
Minden sort egy új sor (\n) választ el.
-
Minden adatpontot egy vessző (,) választ el.
A CSV azonban nem korlátozódik a vesszők határolóként való használatára. Egyéb gyakori határolók közé tartoznak a kettőspontok (:), a pontosvesszők (;) és a tabulátorok (\td).
3. lépés – CSV olvasása
Ebben a szakaszban bemutatjuk egy olyan mintaprogram megvalósítását, amely adatokat olvas be és elemez a CSV-fájlból.
Hozzon létre egy új JavaScript fájlt:
|
1 |
touch read_csv.js |
Nyissa meg a fájlt a kedvenc szövegszerkesztőjében:
|
1 |
nano read_csv.js |
Először importálni fogjuk a fs és csv-parse modulokat:
|
1 2 |
const fs = require("fs"); const { parse } = require("csv-parse"); |
Itt,
-
Először az fs változóhoz hozzárendeljük az fs objektumot, amelyet a Node.js require() metódus ad vissza a modul importálásakor.
-
Ezután a parse metódust kinyerjük a require() metódus által visszaadott objektumból a parse változóba a destrukturáló szintaxis.
Ezután hozzáadjuk a kódokat a CSV-fájl beolvasásához:
|
1 2 3 4 5 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) |
Itt,
-
Meghívjuk a createReadStream() metódust az fs modulból, és argumentumként átadjuk az olvasni kívánt CSV-fájlt. Ezután létrehoz egy olvasható streamet a nagyobb fájl kisebb darabokra bontásával.
-
A stream létrehozása után a pipe() metódus továbbítja a stream adatok darabjait egy másik streamnek. Ez az új stream a parse() metódus meghívásakor jön létre a csv-modulból.
-
A csv-modul egy olvasható/írható transzformációs streamet alkalmaz, amely fogad egy adatdarabot, és átalakítja azt egy másik formátumba.
-
A parse() metódus tulajdonságokkal rendelkező objektumokat fogad el. Az objektum tovább feldolgozza az elemzett adatokat. Itt az objektum a következő tulajdonságokat veszi fel:
-
delimiter: Az értékek elválasztására szolgáló határoló karakter. A cél CSV-nk esetében ez a vessző (,).
-
from_line: Az a sorszám, ahonnan az elemző elkezdi az elemzést. A megadott 2-es értékkel az elemző kihagyja az 1. sort, és a 2. sornál kezd. Ezzel az elrendezéssel elkerüljük, hogy az oszlopnevek bekerüljenek az elemzett adatok közé.
-
Ezután csatolni fogunk egy streaming eseményt a Node.js on() metódusával:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Itt,
-
Egy bizonyos esemény kiváltásakor a streaming esemény lehetővé teszi egy metódus számára, hogy feldolgozzon egy adatdarabot.
-
Amikor a parse() metódus által elemzett adatok készen állnak a felhasználásra, az kiváltja a data eseményt.
-
Az adatok eléréséhez egy visszahívást (callback) adunk át az on() metódusnak, amely egy row paramétert vesz fel.
-
A row paraméter egy adatdarab tömb formájában (az elemzés eredménye).
-
Végül az adatok naplózásra kerülnek a konzolon a console.log().
A program befejezéséhez további stream eseményeket adunk hozzá a hibák kezelésére, és egy sikeres üzenet kiírására, amikor a CSV-fájl összes adata elfogyott. Frissítse a kódot az alábbiak szerint:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Itt,
-
Az end esemény akkor váltódik ki, amikor a CSV-fájlban lévő összes adat feldolgozásra került. Ez a következő metódus meghívását eredményezi: console.log() metódus, amely kiír egy sikeres üzenetet.
-
Az error esemény akkor váltódik ki, ha hiba lép fel a CSV-adatok elemzése során. Ez a következő metódus meghívását eredményezi: console.log() metódus, amely kiír egy hibaüzenetet.
A végleges kódnak így kell kinéznie:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const fs = require("fs"); const { parse } = require("csv-parse"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
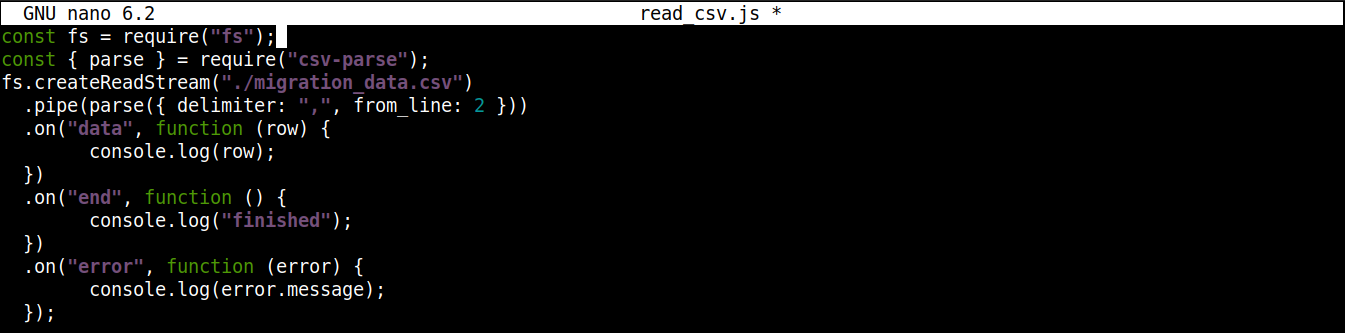
Mentse a fájlt, és zárja be a szerkesztőt. Most már készen állunk a program végrehajtására. Futtassa a Node.js használatával:
|
1 |
node read_csv.js |
A kimenetnek valahogy így kell kinéznie:

Vegye figyelembe, hogy az adatok feldolgozása, átalakítása és konzolra történő kiírása megtörténik. Mivel ez egy folyamatos folyamat, úgy fog tűnni, mintha az adatok letöltése zajlana, ahelyett, hogy a kimenet egyszerre jelenne meg.
4. lépés – CSV-adatok átvitele adatbázisba
Eddig megtanultuk, hogyan kell elemezni egy CSV-fájlt a node-csv használatával. Ez a szakasz bemutatja az elemzett adatok átvitelét egy adatbázisba (SQLite).
Hozzon létre egy új JavaScript-fájlt az adatbázissal való interakcióhoz:
|
1 |
touch csv-to-sqlite3.js |
Most nyissa meg a fájlt egy szövegszerkesztőben:
|
1 |
nano csv-to-sqlite3.js |
![]()
A programunkat a következő kódokkal indítjuk:
|
1 2 3 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; |

Itt,
-
Az első sorban importáljuk a fs modult.
-
A harmadik sorban a filepath változó tartalmazza az SQLite adatbázis elérési útját.
-
Ezen a ponton az adatbázis még nem létezik. Azonban szükség lesz rá, amikor a node-sqlite3.
Ezután adja hozzá a következő sorokat az SQLite adatbázishoz való kapcsolat létrehozásához:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } console.log("Sikeresen csatlakozott az adatbázishoz"); }); return db; } } |
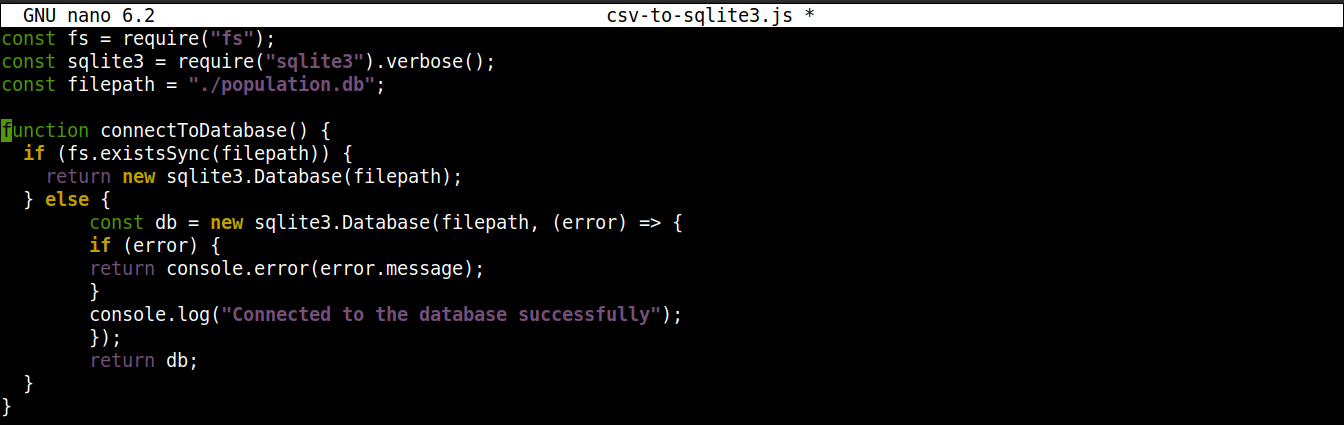
Itt,
-
A connectoToDatabase() metódus kapcsolatot létesít az adatbázissal.
-
A connectToDatabase() függvényen belül meghívjuk a existsSync() metódust az fs modulból egy if utasításon belül. Az if utasítás ellenőrzi az adatbázis létezését a megadott helyen.
-
Ha a feltétel kiértékelése true, akkor a Database() osztály a node-sqlite3 modulból példányosításra kerül. Miután a kapcsolat létrejött, a függvény egy objektumot ad vissza és kilép.
-
Ha a feltétel kiértékelése false (az adatbázis nem létezik), akkor a végrehajtás az else blokkra ugrik. Ott a Database() osztály két argumentummal inicializálódik: az adatbázisfájl elérési útjával és egy callback függvénnyel.
-
Alapvetően az adatbázis létrejön, ha még nem létezik. Ha azonban a létrehozási folyamat során bármilyen hiba lép fel, beállítja a error objektumot, és kiírja a hibaüzenetet.
Ezután bemutatjuk a kódokat egy tábla létrehozásához, ha az adatbázis nem létezik:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } createTable(db); console.log("Sikeresen csatlakozott az adatbázishoz"); }); return db; } } function createTable(db) { db.exec(` CREATE TABLE migration ( year_month VARCHAR(10), month_of_release VARCHAR(10), passenger_type VARCHAR(50), direction VARCHAR(20), sex VARCHAR(10), age VARCHAR(50), estimate INT ) `); } module.exports = connectToDatabase(); |
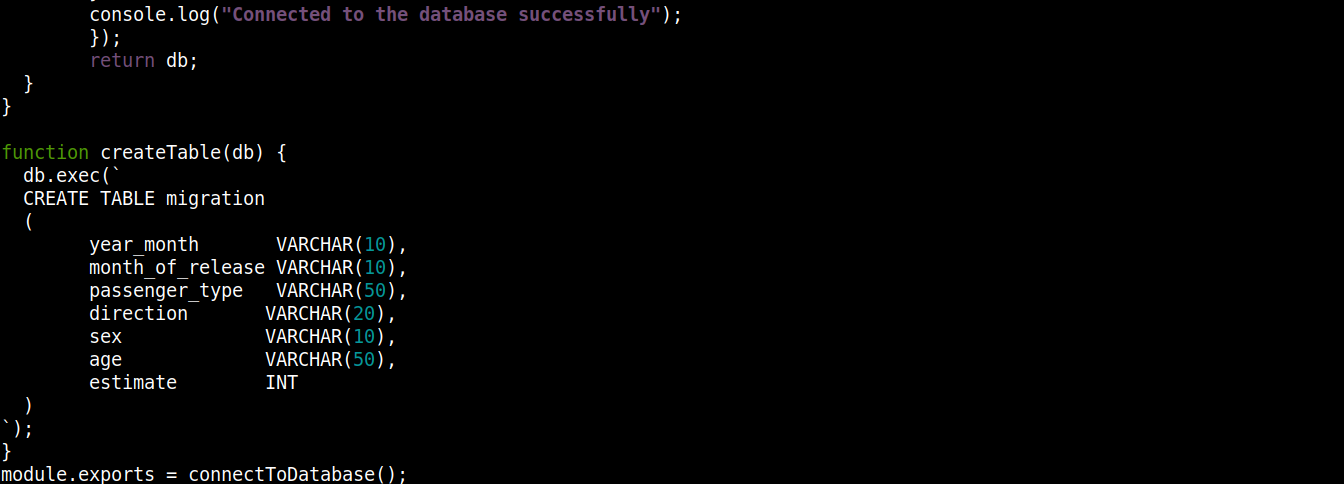
Itt,
-
A connectToDatabase() meghívja a createTable() függvényet, amely argumentumként fogadja a db változóban tárolt objektumot.
-
A connectToDatabase() kívül definiáltuk a createTable() metódust, amely paraméterként fogadja a db kapcsolat objektumot.
-
A exec() metódus a db objektumon egy SQL utasítást vár argumentumként. Ezen az SQL utasításon belül definiáltuk a migration tábla létrehozását 7 oszloppal, ahol minden oszlop megfelel a migration_data.csv fájl oszlopfejléceinek.
-
Végül meghívjuk a connectToDatabase() metódust, és exportáljuk az általa visszaadott kapcsolat objektumot, hogy más fájlokban is használhassuk.
Mentse el a fájlt, és zárja be a szerkesztőt.
Ezután egy másik programot fogunk létrehozni az elemzett adatok adatbázisba történő beillesztésére:
|
1 |
nano insert_data.js |
Írja be a következő kódot a insert_data.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const fs = require("fs"); const { parse } = require("csv-parse"); const db = require("./csv-to-sqlite3"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { db.serialize(function () { db.run( `INSERT INTO migration VALUES (?, ?, ? , ?, ?, ?, ?)`, [row[0], row[1], row[2], row[3], row[4], row[5], row[6]], function (error) { if (error) { return console.log(error.message); } console.log(`Row inserted, ID: ${this.lastID}`); } ); }); }); |
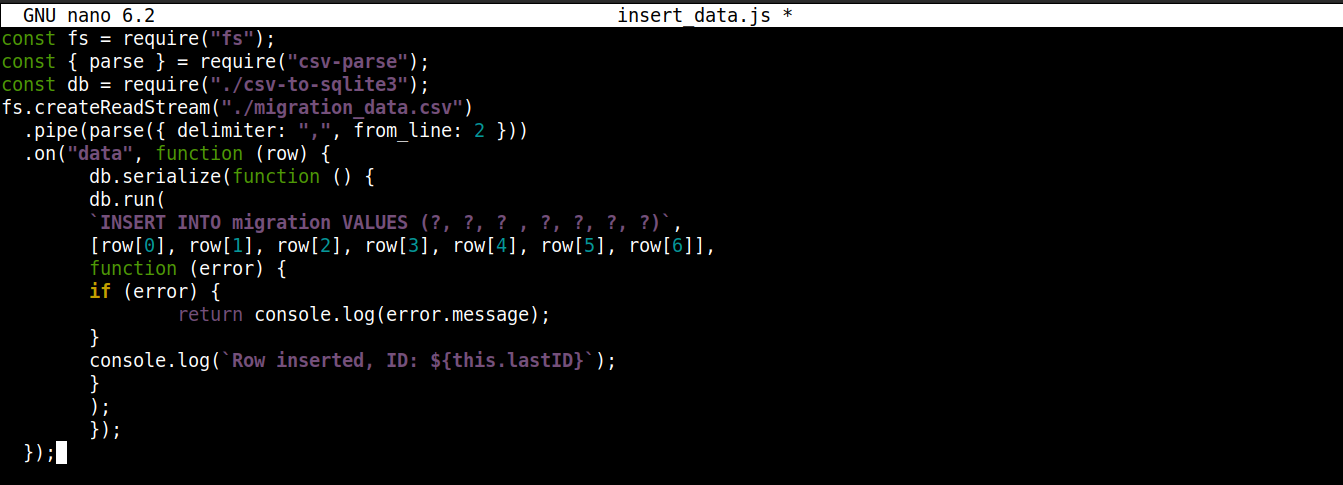
Itt,
-
A kapcsolat objektumot, amelyet innen kaptunk: csv-to-sqlite3.js, a következő változóban tároljuk: db.
-
A (fs modul streamhez csatolt) data esemény callback-en belül meghívjuk a serialize() metódust a kapcsolat objektumon. Ez biztosítja, hogy az egyik SQL utasítás végrehajtása befejeződjön, mielőtt a következő elkezdődne, megakadályozva az adatbázis versenyhelyzeteit (amikor a rendszer egyszerre futtat egymással versengő műveleteket).
-
A serialize() három argumentumot fogad el:
-
Az első argumentum az SQL utasítás.
-
A második argumentum egy tömb.
-
A harmadik argumentum egy callback, amely akkor fut le, amikor az adatok sikeresen vagy sikertelenül beillesztésre kerülnek az adatbázisba.
-
Készen állunk a program futtatására. Futtassa a insert_data.js fájlt a Node.js használatával:
|
1 |
node insert_data.js |
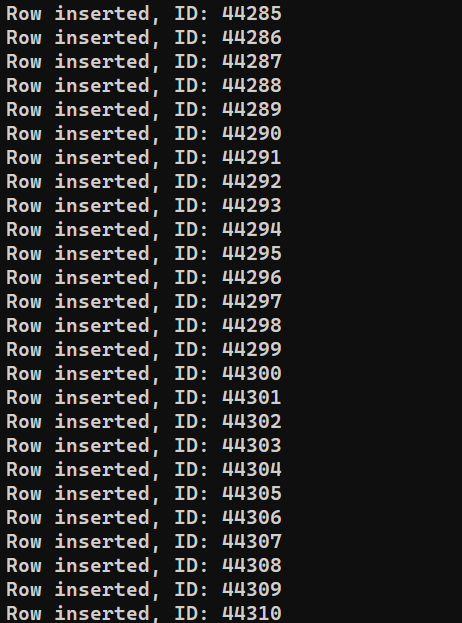
A rendszer teljesítményétől függően a folyamat befejezése eltarthat egy ideig. A befejezés után azonban a kimenetnek valahogy így kell kinéznie:
5. lépés – Adatok írása CSV-be
Az előző szakasz után van egy adatbázisunk, amely tartalmazza az összes olyan rekordot, amelyet a migration_data.csv. Ebben a szakaszban be fogjuk olvasni az adatokat az adatbázisból, és egy külön CSV-fájlba fogjuk írni őket.
Hozzon létre egy új JavaScript-fájlt a program tárolásához:
|
1 |
nano write_csv.js |
Először adja hozzá a következő sorokat az fs és a csv-stringify importálásához, valamint az adatbázis-kapcsolati objektum importálásához innen: csv-to-sqlite3.js:
|
1 2 3 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); |
Ezután hozzáadunk egy változót, amely a kiírandó CSV-fájl nevét tartalmazza, valamint egy írható streamet:
|
1 2 3 4 5 6 7 8 9 10 11 |
const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; |
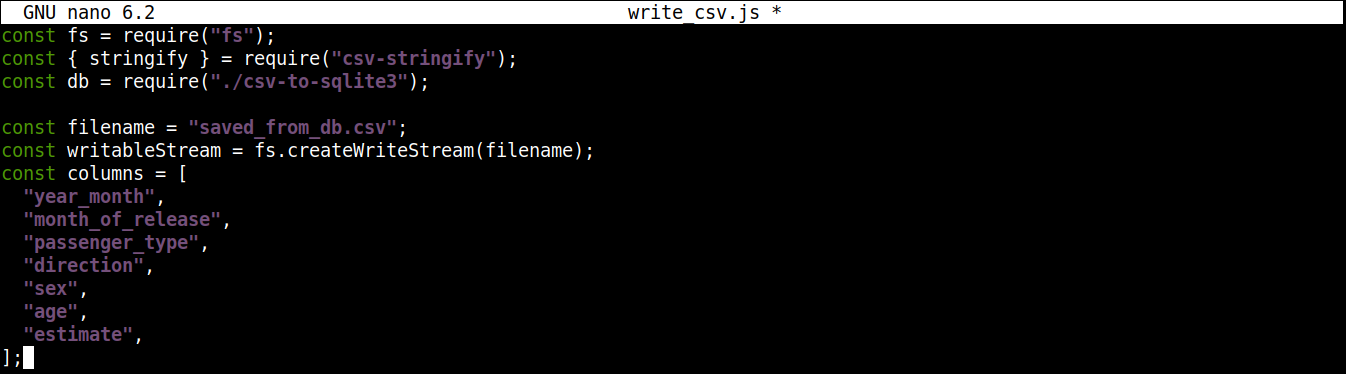
Itt,
-
A createWriteStream() metódus argumentumként fogadja a kiírandó fájlnevet. A fájlt a következőképpen fogjuk elnevezni: saved_from_db.csv.
-
A column változó egy olyan tömböt tárol, amely a CSV-adatok fejlécének összes nevét tartalmazza.
Ezután adja hozzá a következő kódsorokat, hogy beolvassa az adatokat az adatbázisból, és beírja azokat a saved_from_db.csv-be::
|
1 2 3 4 5 6 7 8 9 10 11 |
const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("finished writing to CSV"); |
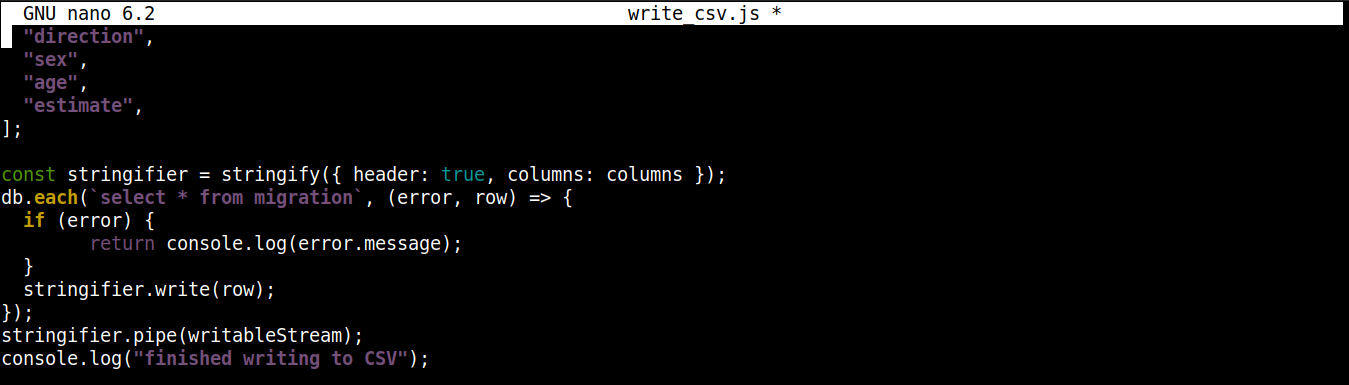
Itt,
-
Meghívjuk a stringify() metódust egy objektummal mint argumentummal. Ez egy olyan transzformációs streamet eredményez, amely az adatokat objektumból CSV formátumba konvertálja. A stringify() metódusnak átadott objektumnak két tulajdonsága van:
-
header: Logikai (Boolean) értéket fogad el. Ha az érték true, akkor létrejön egy fejléc.
-
columns: Egy olyan tömböt fogad el, amely a CSV-fájl első sorába írandó oszlopneveket tartalmazza, ha a header értéke true.
-
-
A each() metódus a csv-to-sqlite3 kapcsolati objektumból két argumentummal lesz meghívva: az SQL utasítással (adatok beolvasása az adatbázisból) és egy visszahívási függvénnyel (callback, amely a sikert/hibát kezeli).
-
A(z) each(), minden egyes iterációjakor a pipe() (a stringifier streamből) elkezdi az adatokat darabokban küldeni a writableStream írható streambe. Ezután minden egyes adatdarab beíródik a saved_from_db.csv fájlba..
-
Amikor az összes adat beíródott a CSV-fájlba, egy sikeres befejezést jelző üzenet jelenik meg a konzolon.
A végleges kódnak így kell kinéznie:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("befejeződött a CSV-be írás"); |
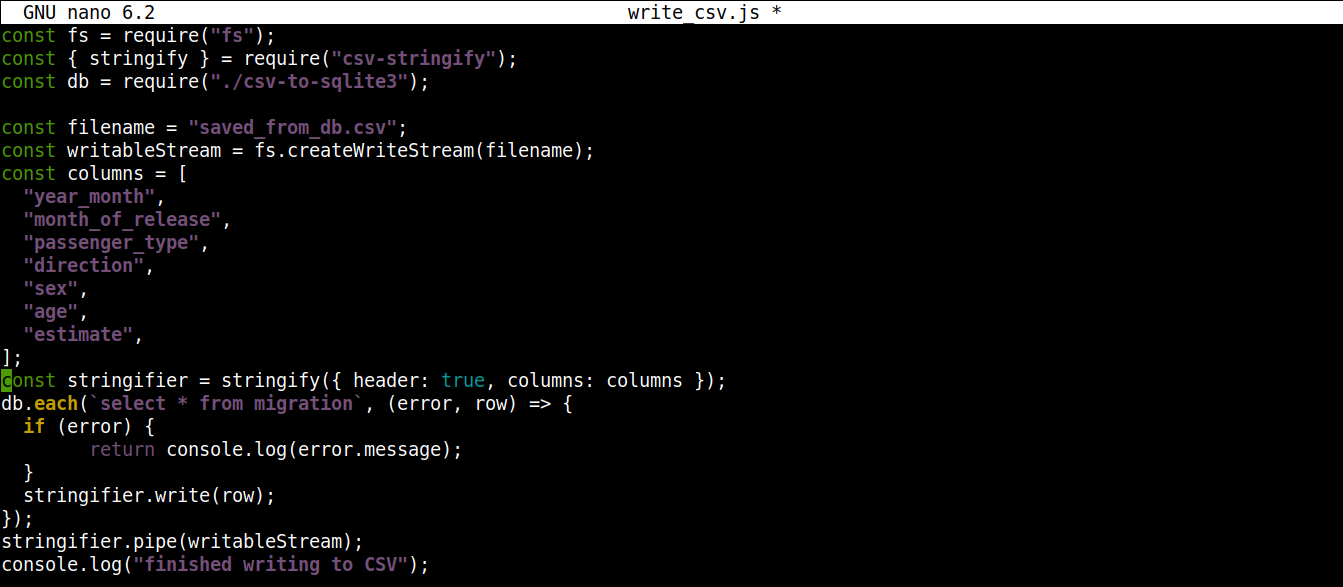
Mentse el a fájlt, és zárja be a szerkesztőt. Most már futtathatjuk a programot a Node.js használatával:
|
1 |
node write_csv.js |
Annak ellenőrzéséhez, hogy az adatok exportálása sikeres volt-e, ellenőrizze a következő fájl tartalmát: saved_from_db.csv:
|
1 |
cat saved_from_db.csv | less |
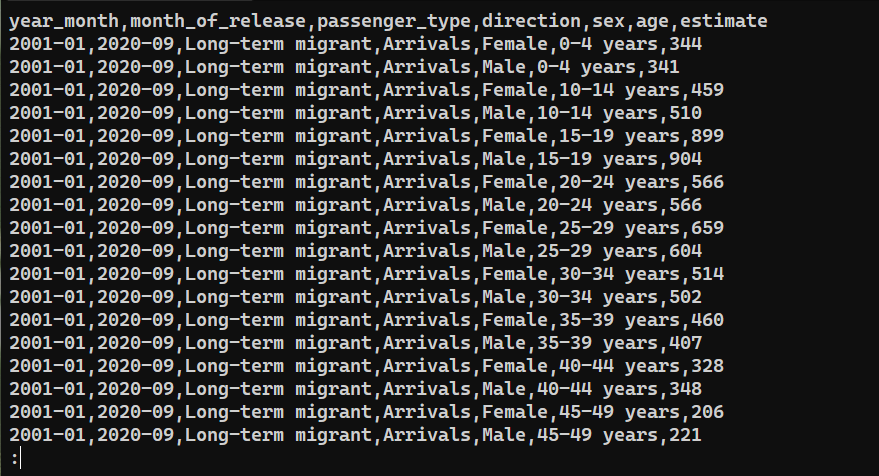
Záró gondolatok
Ebben az útmutatóban bemutattuk a CSV-fájlok kezelését Node.js-ben a node-csv és a node-sqlite3 modulok használatával. Több programot is létrehoztunk különböző feladatok elvégzésére, például adatok elemzésére CSV-ből, adatok feltöltésére egy SQLite adatbázisba, valamint adatok írására egy új CSV-fájlba.
Ez az útmutató csak egy kis részét mutatja be a node-csv modul képességeinek. Tudjon meg többet az összes funkciójáról itt: CSV Project. Ha többet szeretne megtudni a node-sqlite3-ról, tekintse meg a hivatalos dokumentációt a GitHubon. Egy másik említésre méltó modul az event-stream a streamekkel való munka egyszerűsítésére.
Szeretné továbbfejleszteni Node.js projektjét? Íme néhány Node.js oktatóanyag, amelyet érdemes megnéznie:
-
Node.js modulok használata az npm és a package.json segítségével: Útmutató
-
Hogyan telepítsünk Node.js (Express.js) alkalmazást Dockerrel Ubuntu 20.04-en
-
PostgreSQL összekapcsolása Node.js alkalmazásokkal: Útmutató
Kellemes kódolást!
Hozzászólások
Még nincsenek hozzászólások. Legyen Ön az első.