

تتيح CloudSigma للعملاء إضافة وحدات معالجة الرسومات (GPUs) إلى أجهزتهم الافتراضية واستخدام حوسبة عالية الأداء وفعالة من حيث التكلفة يمكنها تلبية أعباء العمل الأكثر تطلبًا. يكمن جوهر عروض وحدات معالجة الرسومات (GPU) من CloudSigma في وحدة معالجة الرسومات NVIDIA A100 Tensor Core المحسنة لـ HPC و AI وتحليلات البيانات. يتفوق A100 على NVIDIA TESLA V100 ويتميز بميزات جديدة يمكن لتطبيقات AI الاستفادة منها بشكل كامل. نحن نسمح للعملاء بإنشاء أجهزة افتراضية (VMs) محسنة لـ NVIDIA A100 بسهولة في وضع المرور (passthrough mode) بحيث يكون لنسخ الأجهزة الافتراضية (VM) تحكم مباشر في وحدة/وحدات معالجة الرسومات (GPU/s) وذاكرتها المدمجة.
حالات الاستخدام
أدى نمو التطبيقات كثيفة الحوسبة التي تعمل في السحابة إلى حدوث طفرة مؤخرًا في الحوسبة السحابية المسرعة بواسطة وحدات معالجة الرسومات (GPU). وتشمل هذه التطبيقات تدريب واستدلال التعلم العميق للذكاء الاصطناعي (AI)، وتحليلات البيانات، والحوسبة العلمية، وعلم الجينوم، ورسم الرسومات، والألعاب، على سبيل المثال لا الحصر. من توسيع نطاق تدريب الذكاء الاصطناعي (AI) والحوسبة العلمية إلى توسيع نطاق تطبيقات الاستدلال وتمكين الذكاء الاصطناعي التخاطبي في الوقت الفعلي، توفر وحدات معالجة الرسومات (GPUs) القوة اللازمة لتسريع العديد من أعباء العمل المعقدة وغير المتوقعة التي تعمل في السحابة.
تمثل وحدة معالجة الرسومات NVIDIA A100 Tensor Core قفزة هائلة إلى الأمام، حيث توفر تسريعًا غير مسبوق للذكاء الاصطناعي (AI)، وتحليلات البيانات، و HPC على كافة المستويات. بدعم من معمارية NVIDIA Ampere Architecture، يوفر A100 أداءً أعلى بنسبة تصل إلى 20X مقارنة بالجيل السابق. تتيح CloudSigma إصدار الذاكرة بسعة 80GB، وهو أسرع نطاق ترددي في العالم بأكثر من 2 تيرابايت في الثانية (TB/s) لتشغيل أكبر النماذج ومجموعات البيانات.
تعد وحدات معالجة الرسومات NVIDIA GPUs من بين المحركات الحوسبية الرائدة التي تدعم الذكاء الاصطناعي (AI) من خلال توفير تسريع كبير لأعباء عمل تدريب واستدلال الذكاء الاصطناعي (AI). بالإضافة إلى ذلك، تعمل وحدات معالجة الرسومات NVIDIA GPUs على تسريع العديد من أنواع تطبيقات وأنظمة HPC وتحليلات البيانات، مما يحول البيانات إلى رؤى.
الذكاء الاصطناعي (AI) و HPC
قم بتدريب نماذج التعلم الآلي المعقدة بشكل أسرع وأكثر كفاءة باستخدام تسريع وحدات معالجة الرسومات (GPU). تعامل مع المهام الكثيفة البيانات وحقق طفرات في الابتكار القائم على الذكاء الاصطناعي (AI).تعد NVIDIA AI Enterprise مجموعة برمجيات متكاملة ومصممة خصيصًا للسحابة للذكاء الاصطناعي (AI) وتحليلات البيانات، وهي محسنة لتمكين أي مؤسسة من استخدام الذكاء الاصطناعي (AI). وهي معتمدة للنشر على السحابة العامة وتتضمن دعمًا عالميًا للمؤسسات لإبقاء مشاريع الذكاء الاصطناعي (AI) على المسار الصحيح. يتيح A100 للباحثين تقديم نتائج واقعية بسرعة ونشر الحلول في بيئة الإنتاج على نطاق واسع.
تدريب التعلم العميق
يتطلب تدريب نماذج الذكاء الاصطناعي (AI) قوة حوسبة هائلة وقابلية للتوسع. توفر نوى NVIDIA A100 Tensor Cores مع Tensor Float (TF32) أداءً أعلى بنسبة تصل إلى 20X مقارنة بـ NVIDIA Volta دون أي تغييرات في الكود، وزيادة إضافية بمقدار 2X مع الدقة المختلطة التلقائية و FP16.
يمكن حل عبء عمل تدريبي مثل BERT على نطاق واسع في أقل من دقيقة بواسطة 2,048 من وحدات معالجة الرسومات A100 GPUs، وهو رقم قياسي عالمي للوقت المستغرق للوصول إلى الحل.
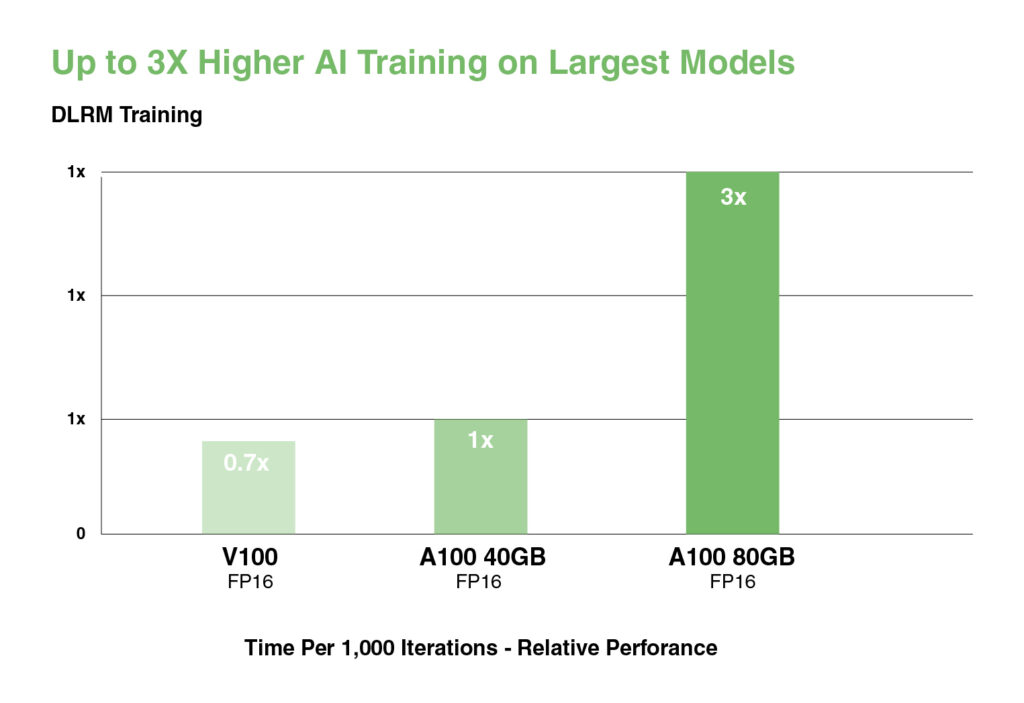
بالنسبة لأكبر النماذج التي تحتوي على جداول بيانات ضخمة مثل نماذج توصية التعلم العميق (DLRM)، يصل A100 80GB إلى ما يصل إلى 1.3 TB من الذاكرة الموحدة لكل عقدة ويوفر زيادة في الإنتاجية تصل إلى 3X مقارنة بـ A100 40GB.
ريادة NVIDIA في MLPerf، حيث سجلت أرقامًا قياسية متعددة للأداء في المعيار القياسي على مستوى الصناعة لتدريب الذكاء الاصطناعي (AI).
استدلال التعلم العميق
يقدم A100 ميزات رائدة لتحسين أعباء عمل الاستدلال. فهو يسرع نطاقًا كاملاً من الدقة من FP32 إلى INT4. تتيح تقنية Multi-Instance GPU (MIG) لشبكات متعددة العمل في وقت واحد على جهاز A100 واحد لتحقيق الاستخدام الأمثل لموارد الحوسبة. ويوفر دعم التناثر الهيكلي (structural sparsity) أداءً أعلى بنسبة تصل إلى 2X بالإضافة إلى مكاسب أداء الاستدلال الأخرى لـ A100.
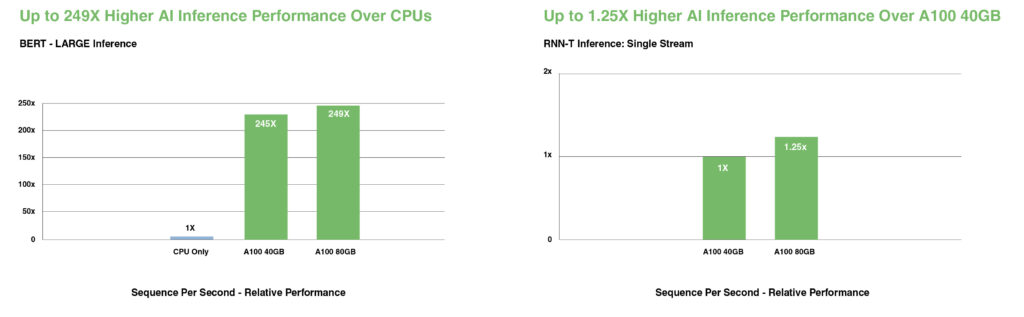
في نماذج الذكاء الاصطناعي التخاطبي المتطورة مثل BERT، يسرع A100 إنتاجية الاستدلال بما يصل إلى 249X مقارنة بوحدات المعالجة المركزية (CPUs).
في النماذج الأكثر تعقيدًا والمقيدة بحجم الدفعة (batch-size)، مثل RNN-T للتعرف التلقائي على الكلام، فإن سعة الذاكرة المتزايدة لـ A100 80GB تضاعف حجم كل MIG وتوفر إنتاجية أعلى تصل إلى 1.25X مقارنة بـ A100 40GB.
تم إثبات أداء NVIDIA الرائد في السوق في MLPerf Inference. يقدم A100 أداءً أعلى بمقدار 20X لتوسيع هذه الريادة بشكل أكبر.
الحوسبة عالية الأداء
لفتح آفاق اكتشافات الجيل القادم، يتطلع العلماء إلى عمليات المحاكاة لفهم العالم من حولنا بشكل أفضل.
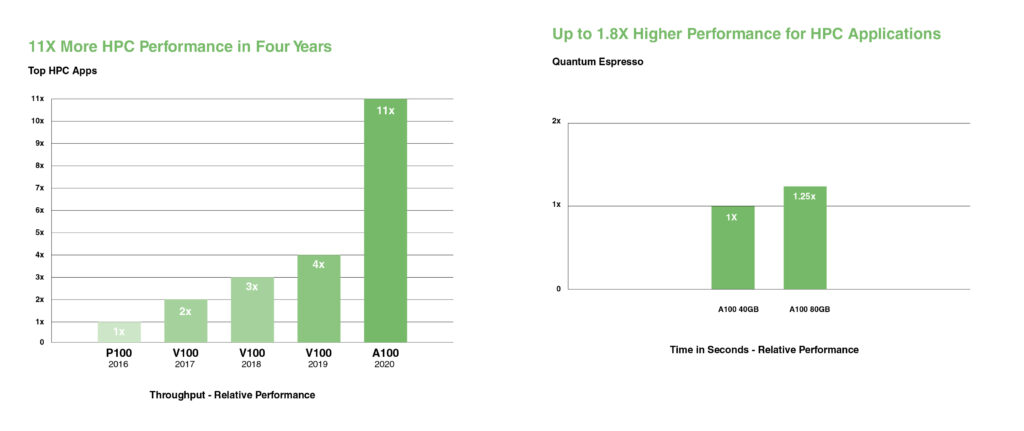
يقدم NVIDIA A100 نوى Tensor Cores مزدوجة الدقة لتحقيق أكبر قفزة في أداء HPC منذ إدخال وحدات معالجة الرسومات (GPUs). مع ذاكرة GPU الأسرع بسعة 80GB، يمكن للباحثين تقليل محاكاة مزدوجة الدقة مدتها 10 ساعات إلى أقل من أربع ساعات على A100. يمكن لتطبيقات HPC الاستفادة من TF32 لتحقيق إنتاجية أعلى تصل إلى 11X لعمليات ضرب المصفوفات الكثيفة أحادية الدقة.
بالنسبة لتطبيقات HPC ذات مجموعات البيانات الأكبر، توفر الذاكرة الإضافية لـ A100 80GB زيادة في الإنتاجية تصل إلى 2X مع Quantum Espresso، وهو برنامج محاكاة للمواد. هذه الذاكرة الهائلة ونطاقها الترددي غير المسبوق يجعل من A100 80GB المنصة المثالية لأعباء عمل الجيل القادم.
تحليلات البيانات عالية الأداء
يحتاج علماء البيانات إلى القدرة على تحليل مجموعات البيانات الضخمة وتصورها وتحويلها إلى رؤى. ولكن غالباً ما تتعثر حلول التوسيع الأفقي بسبب تشتت مجموعات البيانات عبر خوادم متعددة.
توفر الخوادم المسرعة باستخدام A100 قوة الحوسبة اللازمة — ذاكرة هائلة، ونطاق ترددي للذاكرة يزيد عن 2 TB/sec، وقابلية للتوسع مع NVIDIA® NVLink® و NVSwitch™ — لمعالجة أعباء العمل هذه. وبالاقتران مع InfiniBand و NVIDIA Magnum IO™ ومجموعة RAPIDS™ من المكتبات مفتوحة المصدر، بما في ذلك RAPIDS Accelerator لـ Apache Spark لتحليلات البيانات المسرعة بواسطة GPU، تعمل منصة مركز بيانات NVIDIA على تسريع أعباء العمل الضخمة هذه بمستويات غير مسبوقة من الأداء والكفاءة.
في اختبار قياسي لتحليلات البيانات الضخمة، قدم A100 80GB رؤى بزيادة قدرها 2X مقارنة بـ A100 40GB، مما يجعله مناسباً تماماً لأعباء العمل الناشئة ذات أحجام البيانات المتفجرة.
عمليات المحاكاة العلمية: تسريع الأبحاث العلمية وعمليات المحاكاة، مما يتيح الحصول على رؤى واكتشافات أسرع في مجالات الفيزياء والكيمياء وعلوم البيئة.
الإعلام والترفيه: تصيير الرسومات ومقاطع الفيديو والرسوم المتحركة عالية الدقة بسرعة فائقة. تقديم تجارب بصرية استثنائية لجمهورك دون المساومة على الجودة.
النمذجة المالية: تحليل مجموعات البيانات الضخمة وإجراء نمذجة مالية معقدة بسرعة لا مثيل لها، مما يوفر رؤى بالغة الأهمية لاتخاذ قرارات مدروسة.
التعليقات
لا توجد تعليقات بعد. كن أول من يعلق.